
Rのデータハンドリングは利用パッケージに合わせた「データのクラスや構造」に注意が必要です。パッケージヘルプのデータではうまく動くのに、自身で準備したデータでは期待した結果が出力されない。そんな経験はないでしょうか。
そんな場合は、strコマンドで用意したデータの構造を確認後、as.numericやas.integerなどのコマンドでクラスを変更で解決することが多いです。でも、できればデータの準備時に「データの構造やクラスは整えたい」ものです。
データの構造やクラスを整えるパッケージはいくつかありますが、「文字列データからクラスと構造を整える」ちょっと変わった「iotools」パッケージを紹介します。
パッケージのバージョンは0.1-22。R version 3.2.1でコマンドを確認しています。
パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("iotools")実行コマンドの紹介
詳細はコメント、パッケージヘルプを確認してください。紹介していませんがread.csv.rawコマンドは使用環境によりRごと落ちるかもしれません。ファイルの読み込みは他パッケージの利用をオススメします。
#パッケージの読み込み
library("iotools")
#文字列から行列を作成:.default.formatterコマンド
#\tで行名とデータを区別,データは|で区切ります
TestData <- c("てすと\tB|3|D", "てすと2\tB|3|B", "てすと\tA|1|E")
.default.formatter(TestData)
[,1] [,2] [,3]
てすと "B" "3" "D"
てすと2 "B" "3" "B"
てすと "A" "1" "E"
#以下matrixコマンドと同じ
matrix(c("B", "B", "A", "3", "3", "1", "D", "B", "E"), nrow = 3, ncol = 3,
dimnames = list(c("てすと", "てすと2", "てすと")))
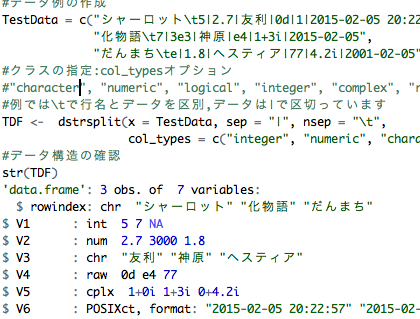
#データのクラスを指定しデータフレームを作成:dstrsplitコマンド
#データ例の作成
#\tで行名とデータを区別,データは|で区切ります
TestData = c("シャーロット\t5|2.7|友利|0d|1|2015-02-05 20:22:57",
"化物語\t7|3e3|神原|e4|1+3i|2015-02-05",
"だんまち\te|1.8|ヘスティア|77|4.2i|2001-02-05")
#クラスの指定:col_typesオプション
#"character", "numeric", "logical", "integer", "complex", "raw", "POSIXct"が指定可能
TDF <- dstrsplit(x = TestData, sep = "|", nsep = "\t",
col_types = c("integer", "numeric", "character", "raw", "complex", "POSIXct"))
#データ構造の確認
str(TDF)
'data.frame': 3 obs. of 7 variables:
$ rowindex: chr "シャーロット" "化物語" "だんまち"
$ V1 : int 5 7 NA
$ V2 : num 2.7 3000 1.8
$ V3 : chr "友利" "神原" "ヘスティア"
$ V4 : raw 0d e4 77
$ V5 : cplx 1+0i 1+3i 0+4.2i
$ V6 : POSIXct, format: "2015-02-05 20:22:57" "2015-02-05 00:00:00" "2001-02-05 00:00:00"
#tapplyコマンドの高速版:ctapplyコマンド
#並び替えを実行するのがポイントです
#データ例の作成
i = rnorm(4e6)
names(i) = as.integer(rnorm(1e6))
#並び替え
i = i[order(names(i))]
#tapplyコマンド処理速度
system.time(tapply(i, names(i), sum))
ユーザ システム 経過
0.383 0.039 0.422
#ctapplyコマンド処理速度
system.time(ctapply(i, names(i), sum))
ユーザ システム 経過
0.027 0.003 0.031少しでも、あなたのウェブや実験の解析が楽になりますように!!

