データを指定した範囲で区分しラベルを付与するパッケージの紹介です。データの区分は大変重要です。簡単に作業できる「fancycut」パッケージはおすすめです。
パッケージバージョンは0.1.2。実行コマンドはwindows 11のR version 4.1.2で確認しています。
パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("fancycut")実行コマンドの紹介
詳細はコマンド、パッケージのヘルプを確認してください。
#パッケージの読み込み
library("fancycut")
###データ例の作成#####
set.seed(220306)
n <- 100
TestData <- data.frame(Group = sample(paste0("Group", 1:5), n, replace = TRUE),
Data1 = sample(c(-5:5, NA), n, replace = TRUE))
#内容確認
head(TestData)
# Group Data1
#1 Group4 2
#2 Group2 -3
#3 Group2 0
#4 Group4 4
#5 Group5 -1
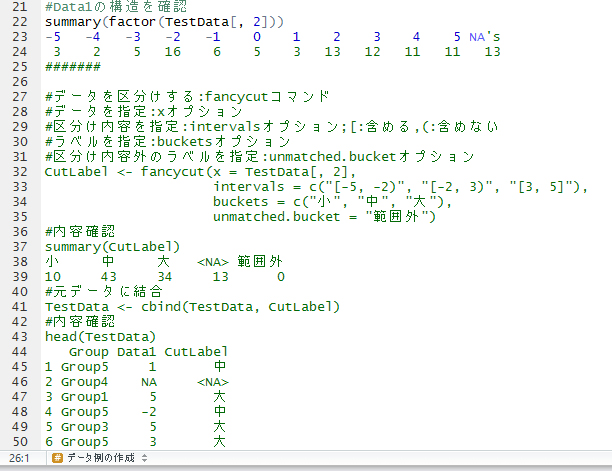
#6 Group1 3
#Data1の分布を確認
summary(factor(TestData[, 2]))
#-5 -4 -3 -2 -1 0 1 2 3 4 5 NA's
#6 10 13 8 4 9 8 11 7 7 6 11
#######
#データを区分けする:wafflecutコマンド
#データを指定:xオプション
#区分け内容を指定:intervalsオプション;[:含める,(:含めない
#ラベルを指定:bucketsオプション
#区分け内容外のラベルを指定:unmatched.bucketオプション
CutLabel <- wafflecut(x = TestData[, 2],
intervals = c("[-5, -2)", "[-2, 3)", "[3, 5]"),
buckets = c("小", "中", "大"),
unmatched.bucket = "範囲外")
#内容確認
summary(CutLabel)
#小 中 大 <NA> 範囲外
#29 40 20 0 11
#元データに結合
TestData <- cbind(TestData, CutLabel)
#内容確認
head(TestData)
# Group Data1 CutLabel
#1 Group4 2 中
#2 Group2 -3 小
#3 Group2 0 中
#4 Group4 4 大
#5 Group5 -1 中
#6 Group1 3 大あなたの解析がとっても楽になりますように!!