ワードファイル、テキストファイル、テキスト付きのPDFファイルを簡単にRへ取り込むことができるパッケージの紹介です。URLアドレスを指定し読み込むことも可能なので便利だと思います。
パッケージバージョンは0.3.0。windows 10のR version 3.3.2で動作を確認しています。
パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("textreadr")実行コマンド
詳細はコマンド、パッケージのヘルプを確認してください。
#パッケージの読み込み
library("textreadr")
#アドレスを指定してファイルをダウンロード:downloadコマンド
#アドレスを設定:urlオプション
#保存場所を指定:locオプション;初期値:tempdir()
#Rで解析:頻度が高い?20のグラフィックスパラメータのまとめ
#https://www.karada-good.net/analyticsr/r-91
#で紹介しているPDFを作業フォルダに保存
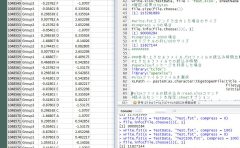
download(url = "https://www.karada-good.net/wp/wp-content/uploads/2015/05/GraphicalParameters.pdf",
loc = paste(as.character(tcltk::tkchooseDirectory(title = "ファイルの保存場所を選択"),
sep = "", collapse ="")))
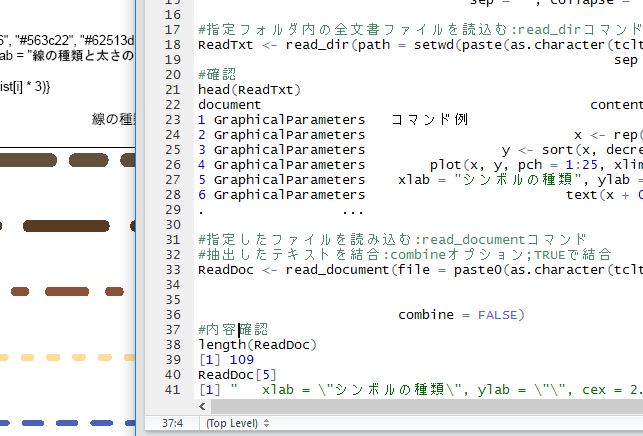
#指定フォルダ内の全文書ファイルを読込む:read_dirコマンド
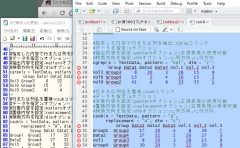
ReadTxt <- read_dir(path = setwd(paste(as.character(tcltk::tkchooseDirectory(title = "フォルダを選択"),
sep = "", collapse =""))))
#確認
head(ReadTxt)
#指定した文書ファイルを読み込む:read_documentコマンド
#抽出したテキストを結合:combineオプション;TRUEで結合
ReadDoc <- read_document(file = paste0(as.character(tcltk::tkgetOpenFile(title = "ファイルを選択",
filetypes = '{"文書ファイル" {".doc" | ".docx" | ".txt" | ".pdf"}}',
initialfile = c("*.*"))), collapse = " "),
combine = FALSE)
#内容確認
length(ReadDoc)
[1] 109
ReadDoc[5]
[1] " xlab = \"シンボルの種類\", ylab = \"\", cex = 2.5, col = \"red\")"あなたの解析が少しでも楽になりますように!!