データ解析時に意外と面倒な行名・列名の操作がラクラクなパッケージの紹介です。文字列操作は正規表現を知っていると作業効率の改善になると考えます。
パッケージバージョンは0.1.900。R version 3.3.2で動作を確認しています。
パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("colr")実行コマンド
詳細はコマンド、パッケージのヘルプを確認してください。
#パッケージの読み込み
library("colr")
###データ例の作成#####
n <- 10
TestData <- data.frame("Group" = sample(paste0("Group", 1:5), n, replace = TRUE),
"Data1" = sample(1:50, n, replace = TRUE),
"Data2" = sample(1:35, n, replace = TRUE),
"Data3" = sample(1:10, n, replace = TRUE),
"Vol.1" = sample(1:50, n, replace = TRUE),
"Vol.2" = sample(1:35, n, replace = TRUE),
"Vol.3" = sample(1:10, n, replace = TRUE))
#行名を付与
rownames(TestData) <- paste0(c("Group", "Data", "Vol"), 1:n)
#内容確認
TestData
Group Data1 Data2 Data3 Vol.1 Vol.2 Vol.3
Group1 Group2 17 20 1 8 26 7
Data2 Group4 27 32 2 20 27 3
Vol3 Group3 8 20 3 28 15 9
Group4 Group4 30 20 3 22 20 9
Data5 Group1 36 29 2 46 31 3
Vol6 Group4 15 2 4 20 15 2
Group7 Group2 18 30 1 47 29 2
Data8 Group3 14 13 9 2 32 4
Vol9 Group2 41 4 8 33 35 1
Group10 Group1 50 11 1 11 4 2
########
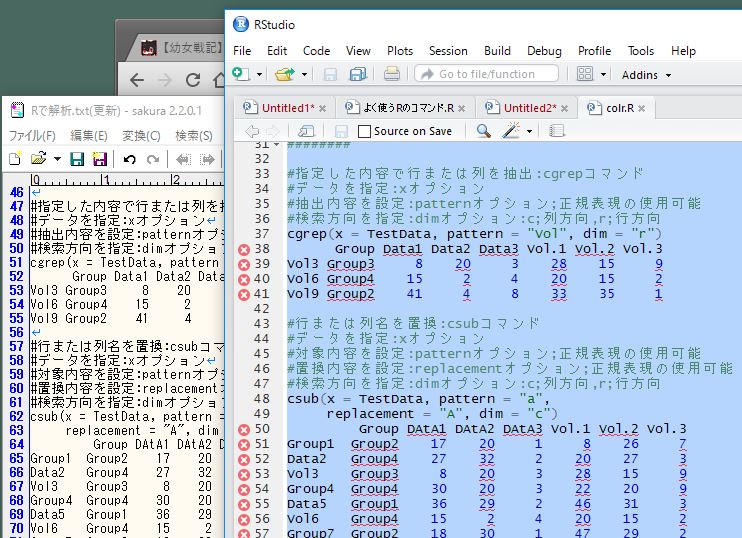
#指定した内容で行または列を抽出:cgrepコマンド
#データを指定:xオプション
#抽出内容を設定:patternオプション;正規表現の使用可能
#検索方向を指定:dimオプション:c;列方向,r;行方向
cgrep(x = TestData, pattern = "Vol", dim = "r")
Group Data1 Data2 Data3 Vol.1 Vol.2 Vol.3
Vol3 Group3 8 20 3 28 15 9
Vol6 Group4 15 2 4 20 15 2
Vol9 Group2 41 4 8 33 35 1
#行または列名を置換:csubコマンド
#データを指定:xオプション
#対象内容を設定:patternオプション;正規表現の使用可能
#置換内容を設定:replacementオプション;正規表現の使用可能
#検索方向を指定:dimオプション:c;列方向,r;行方向
csub(x = TestData, pattern = "a",
replacement = "A", dim = "c")
Group DAtA1 DAtA2 DAtA3 Vol.1 Vol.2 Vol.3
Group1 Group2 17 20 1 8 26 7
Data2 Group4 27 32 2 20 27 3
Vol3 Group3 8 20 3 28 15 9
Group4 Group4 30 20 3 22 20 9
Data5 Group1 36 29 2 46 31 3
Vol6 Group4 15 2 4 20 15 2
Group7 Group2 18 30 1 47 29 2
Data8 Group3 14 13 9 2 32 4
Vol9 Group2 41 4 8 33 35 1
Group10 Group1 50 11 1 11 4 2
###正規表現の例#####
#[]で囲まれた文字のどれかと一致
cgrep(x = TestData, pattern = "[3a]", dim = "r")
Group Data1 Data2 Data3 Vol.1 Vol.2 Vol.3
Data2 Group1 25 32 5 44 9 3
Vol3 Group3 34 11 8 50 15 4
Data5 Group1 43 22 7 22 12 7
Data8 Group4 28 15 9 47 5 8
#^で否定,Data数字を非選択
#[:digit:]数字を意味する
cgrep(x = TestData, pattern = "[^Data[:digit:]]", dim = "r")
Group Data1 Data2 Data3 Vol.1 Vol.2 Vol.3
Group1 Group2 48 32 9 17 14 1
Vol3 Group3 34 11 8 50 15 4
Group4 Group2 42 32 6 24 12 4
Vol6 Group3 15 11 7 50 28 4
Group7 Group3 8 22 9 49 6 1
Vol9 Group4 26 30 8 19 13 9あなたの解析が少しでも楽になりますように!!