パッケージヘルプのタイトルに「図描写とHydrology(水文学)に関係する機能コレクション」と記載されている「berryFunctions」パッケージが他分野でも利用できそうなので紹介します。
水文学を知らなかったので、調べてみると
「水文学は地球上の水循環および分布状況,物理的・化学特性,および生物的環境と水の相互関係を取り扱う学問です。この中の基礎水文学にあたる部分で,自然科学的なアプローチを重視する分野を特に水文科学(Hydrological Sciences)と呼んでいます。」
と日本水文科学会HPで紹介されています。
非常に興味が湧く学問分野です。詳しくは以下の学会を参照ください。
日本水文科学会:http://www.suimon.sakura.ne.jp/about-jahs.html
水文学に関係する「berryFunctions」パッケージの中から、6つの図描写コマンドを紹介します。
パッケージバージョンは1.21.0。実行コマンドはwindows 11のR version 4.1.3で確認しています。
パッケージのインストール
下記、コマンドを実行してください。
install.packages("berryFunctions")実行コマンド
詳細はコメント、パッケージのヘルプを確認してください。
#パッケージの読み込み
library("berryFunctions")
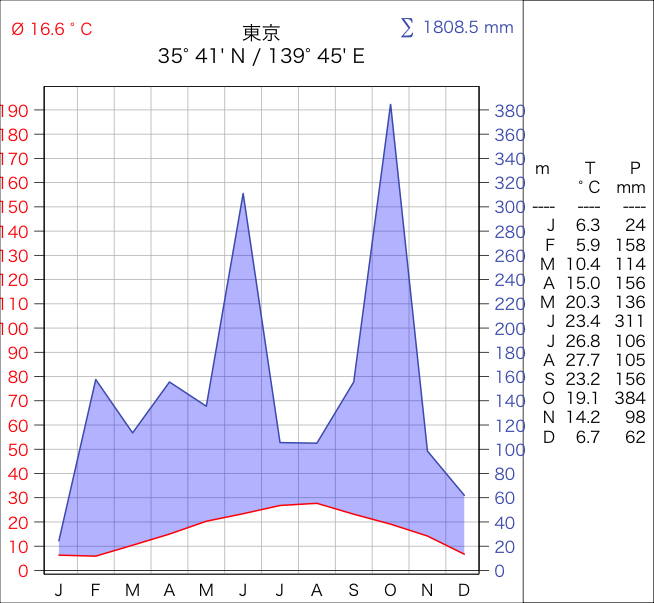
#climateGraphコマンド例
#月別平均の気温と降水量をプロット
climateGraph(temp = c(6.3, 5.9, 10.4, 15.0, 20.3, 23.4, 26.8, 27.7, 23.2, 19.1, 14.2, 6.7),
rain = c(24.5, 157.5, 113.5, 155.5, 135.5, 311, 105.5, 105.0, 155.5, 384.5, 98.5, 62.0),
main = "東京\n35\U00B0 41' N / 139\U00B0 45' E",
colrain = "#4b61ba", textprop = 0.2)
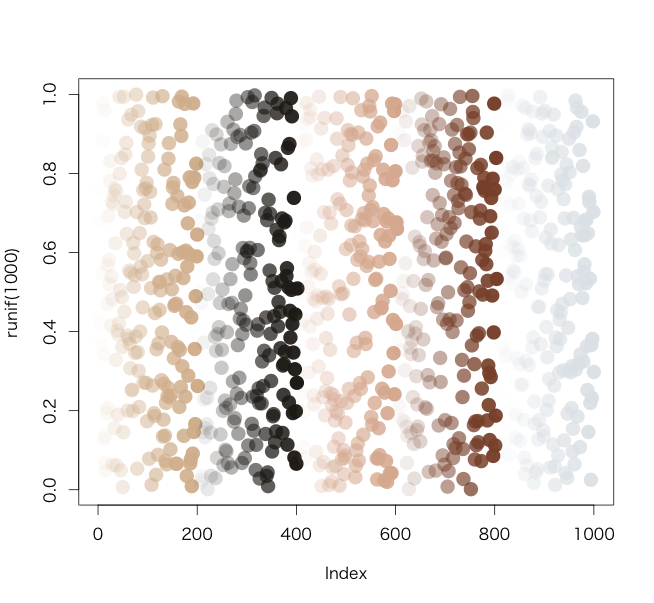
#addAlphaを使用したコマンド例
#シンボルのアルファ値(透明度)を自動で調整
NewColors <- addAlpha(c("#d9bb9c", "#28231e", "#deb7a0", "#8a5136", "#e1e6ea"), 0:200/200)
plot(runif(1000), col = NewColors, pch = 16, cex = 2)
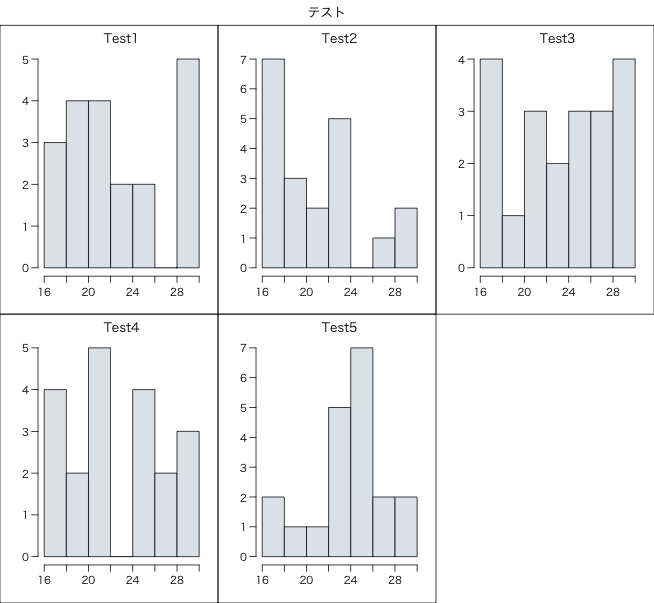
#groupHistコマンド例
#グループ毎の出現数を棒グラフで表示
TestData <- data.frame(value = sample(16:30, 100, replace = TRUE), Name = rep(paste0("Test", 1:5), each = 20))
groupHist(TestData, "value", "Name", col = "#e1e6ea", main = "テスト")
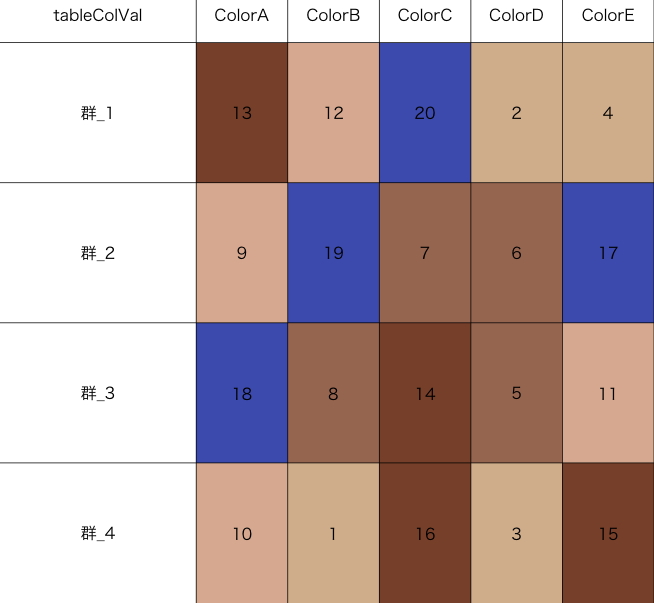
#tableColValコマンド例
#セルの番号総数を色数で分割し背景色を設定しプロット
#セル番号総数20の場合、1:4が"#d9bb9c"、5:9が"#a87963"...となります
#オプションを追加することでpdf出力が可能です:, pdffile = "ファイル名.pdf", pdf = TRUE
TestMatrix <- matrix(sample(1:20, 20, replace = FALSE),
ncol = 5, byrow = TRUE)
colnames(TestMatrix) <- paste0("Color", LETTERS[1:5])
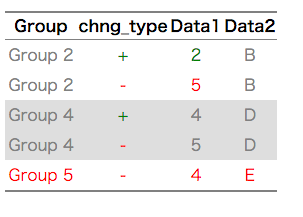
rownames(TestMatrix) <- paste("群", 1:4, sep = "_")
tableColVal(TestMatrix, palette = c("#d9bb9c", "#a87963", "#deb7a0", "#8a5136", "#4b61ba"), pdf = FALSE)
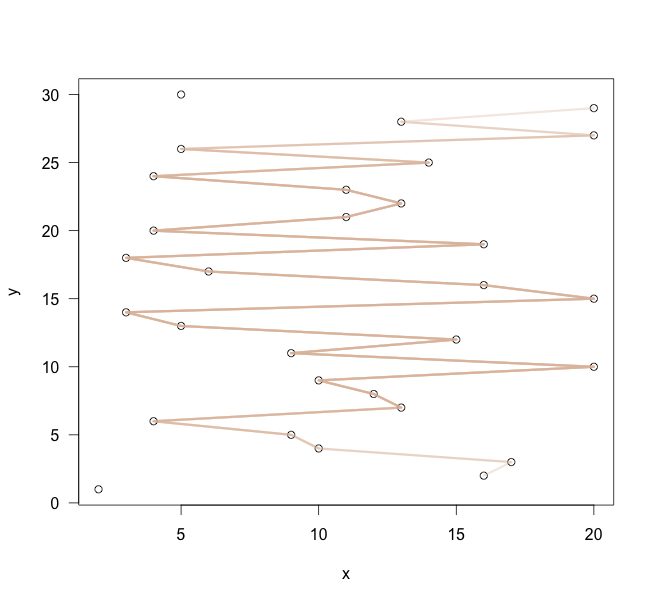
#movAvLinesコマンド例
movAvLines(1:30, sample(1:20, 30, replace = TRUE), col = "#deb7a0", lwd = 3, plot = TRUE)
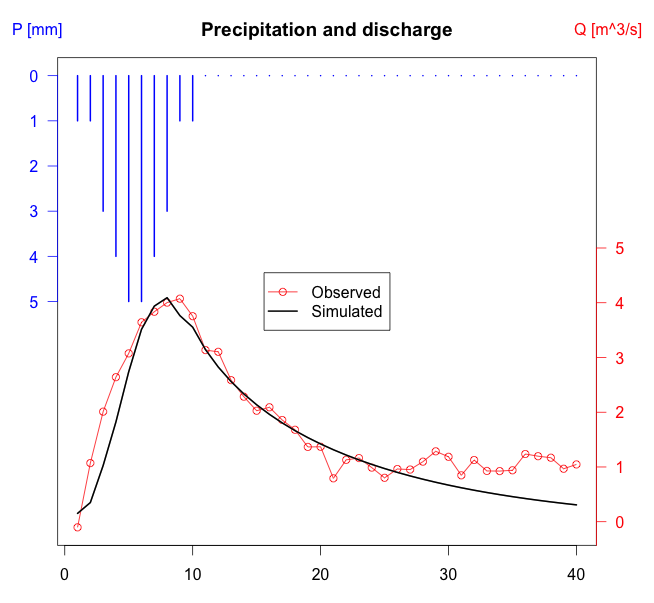
#lscコマンドの例
#estimate parameters for Unit Hydrograph, plot data and simulation: lsc
#単位当たりの水量とシミュレーションによる推定値?水文学にお詳しい先生、解釈法を教授いただけませんでしょうか
QOBS <- dbeta(1:40/40, 3, 10) + rnorm(20, 0.2) + c(seq(0, 1, len = 20), rep(1, 20))
PREC <- c(1, 1, 3, 4, 5, 5, 4, 3, 1, 1, rep(0, 30))
lsc(PREC, QOBS, area = 10)出力例
・climateGraphコマンド
・addAlphaを使用したコマンド
・groupHistコマンド
・tableColValコマンド
・movAvLinesコマンド
・lscコマンド
少しでも、あなたの解析が楽になりますように!!