「違い」のシソーラスを調べると、差異・差・溝・開き・隔たり・異なり・食い違いなど日本語の多様性に改めて驚かされます。しかし、データ解析でオブジェクトの「違い」を正確に判断できないとエラーや致命的な誤解釈の原因となります。
Rのオブジェクト内容の比較方法の例と、便利な「compare」パッケージを紹介します。
違いの判断や結果の再現性は6シグマに近づけたいものです。
パッケージのバージョンは0.2-6。R version 3.2.1でコマンドを確認しています。
パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("compare")実行コマンド
詳細はコマンド、パッケージヘルプを確認してください。
#オブジェクトの完全一致:identicalコマンド
#整数だと
identical(3 - 2, 1)
[1] TRUE
class(3 - 2)
[1] "numeric"
#小数を含むと
identical(3.3 - 2.2, 1.1)
[1] FALSE
class(3.3 - 2.2)
[1] "numeric"
#となります
#小数を含んだ比較として
#ほぼ等しい判断:all.equalコマンド
identical(all.equal(3.3 - 2.2, 1.1), TRUE)
[1] TRUE
identical(all.equal(3.000003 - 2.000002, 1.000001), TRUE)
[1] TRUE
#all.equalコマンドは等しくない場合,その情報を示します
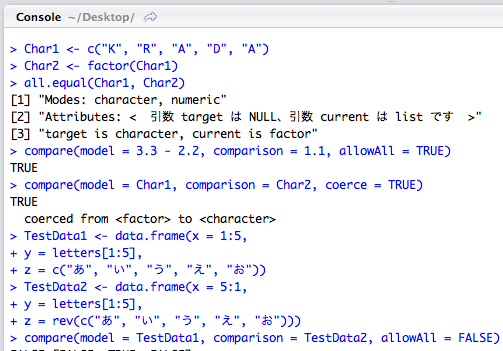
Char1 <- c("K", "R", "A", "D", "A")
Char2 <- factor(Char1)
all.equal(Char1, Char2)
[1] "Modes: character, numeric"
[2] "Attributes: < 引数 target は NULL、引数 current は list です >"
[3] "target is character, current is factor"
###ここからcompareパッケージ#####
#パッケージの読み込み
library("compare")
###compareパッケージの利用#####
#比較対象のクラスを自動で変換:compareコマンド
#数値を丸めるオプション以外を適応:allowAllオプション;初期値TURE
#小数を含む数字の比較
compare(model = 3.3 - 2.2, comparison = 1.1, allowAll = TRUE)
TRUE
#comparisonのクラスをmodelのクラスに変換:coerceオプション
compare(model = Char1, comparison = Char2, coerce = TRUE)
TRUE
coerced from <factor> to <character>
#data.frameの比較も可能です
TestData1 <- data.frame(x = 1:5,
y = letters[1:5],
z = c("あ", "い", "う", "え", "お"))
TestData2 <- data.frame(x = 5:1,
y = letters[1:5],
z = rev(c("あ", "い", "う", "え", "お")))
#確認
compare(model = TestData1, comparison = TestData2, allowAll = FALSE)
FALSE [FALSE, TRUE, FALSE]
#数値を丸めて、並び順を無視してcomparisonのクラスを変換して比較
#数値丸め:roundオプション
#順序を無視:ignoreOrderオプション
compare(model = as.numeric(1:10),
comparison = as.character(10:1 + .1),
round = TRUE, coerce = TRUE, ignoreOrder = TRUE)
#as.numeric(1:10)
#[1] 1 2 3 4 5 6 7 8 9 10
#as.character(10:1 + .1)
#[1] "10.1" "9.1" "8.1" "7.1" "6.1" "5.1" "4.1" "3.1" "2.1" "1.1"
TRUE
coerced from <character> to <numeric>
sorted
rounded少しでも、あなたのウェブや実験の解析が楽になりますように!!