data.frameやmatrixの要約はtableやsplit,listコマンドを組み合わせることで可能ですが、本パッケージは処理の高速化とメモリ利用の効率化が考えられています。
10,000,000 * 3のデータの処理時間をtableコマンドと比較すると約2.8倍速いです。
パッケージバージョンは1.1.9。実行コマンドはR version 4.2.2で確認しています。
パッケージのインストール
下記、コマンドを実行してください。
#パッケージのインストール
install.packages("bigtabulate")実行コマンド
詳細はコメント、パッケージのヘルプを確認してください。
#パッケージの読み込み
library("bigtabulate")
###データ例の作成#####
set.seed(1234)
n <- 10
TestData <- data.frame(Group = sample(paste0("Group", 1:3), n, replace = TRUE),
Data1 = sample(1:5, n, replace = TRUE),
Data2 = sample(11:15, n, replace = TRUE))
########
#データからテーブルを作成:bigtableコマンド
#対象データ列と区分データ列の指定:ccolsオプション
#ccol = (対象データ列, 区分データ列)
BTData <- bigtable(TestData, ccols = c(2, 1))
#classの確認
class(BTData)
[1] "matrix"
#内容の確認
BTData
#基本コマンドで再現:tableコマンド
TData <- table(TestData[, 2], TestData[, 1])
#classの確認
class(TData)
[1] "table"
#内容の確認
TData
#データの組み合わせの位置を検出:bigsplitコマンド
BSData <- bigsplit(TestData, ccols = c(2, 1), splitcol = 1)
#該当する結果がなければnumeric(0)が返される
#確認
BSData
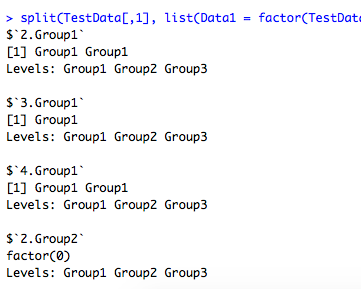
#基本コマンドで再現:splitコマンド
split(TestData[,1], list(Data1 = factor(TestData[,2]), Data2 = TestData[,1]))
###参考,n = 10,000,000のデータ処理時間
n <- 10000000
BigData <- data.frame(Group = sample(paste0("Group", 1:3), n, replace = TRUE),
Data1 = sample(1:5, n, replace = TRUE),
Data2 = sample(11:15, n, replace = TRUE))
#bigtableコマンド
system.time(BTData <- bigtable(BigData, ccols = c(2, 1)))
ユーザ システム 経過
1.101 0.039 1.144
#tableコマンド
system.time(TData <- table(BigData[, 2], BigData[, 1]))
ユーザ システム 経過
2.808 0.164 2.978 少しでも、あなたの解析が楽になりますように!!