文字列データの傾向把握に便利なパッケージの紹介です。収録されているコマンドからCommonPattコマンドを紹介します。
パッケージバージョンは0.3.2。windows 10のR version 4.2.2で動作を確認しています。
パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("GrpString")実行コマンドの紹介
詳細はコマンド、パッケージのヘルプを確認してください。
#パッケージの読み込み
library("GrpString")
###データ例の作成#####
TestVec <- c("Rはからだにいいもの",
"アニメもいいもの", "いいものアニメもいいもの")
#######
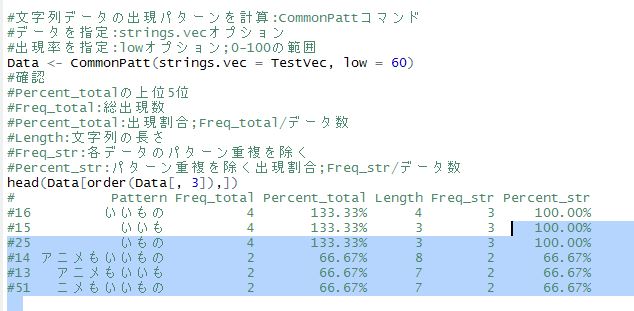
#文字列データの出現パターンを計算:CommonPattコマンド
#データを指定:strings.vecオプション
#出現率を指定:lowオプション;0-100の範囲
Data <- CommonPatt(strings.vec = TestVec, low = 60)
#確認
#Percent_totalの上位5位
#Freq_total:総出現数
#Percent_total:出現割合;Freq_total/データ数
#Length:文字列の長さ
#Freq_str:各データのパターン重複を除く
#Percent_str:パターン重複を除く出現割合;Freq_str/データ数
head(Data[order(Data[, 3]),])
# Pattern Freq_total Percent_total Length Freq_str Percent_str
#16 いいもの 4 133.33% 4 3 100.00%
#15 いいも 4 133.33% 3 3 100.00%
#25 いもの 4 133.33% 3 3 100.00%
#14 アニメもいいもの 2 66.67% 8 2 66.67%
#13 アニメもいいも 2 66.67% 7 2 66.67%
#51 ニメもいいもの 2 66.67% 7 2 66.67%あなたの解析が少しでも楽になりますように!!