Shinyの習作です。「easyPubMed」パッケージなどを利用して論文タイトルからワードクラウドを作成する例です。
Shinyアプリの概要はネットで多く紹介されているので省略します。紹介コマンドをコピー後にRStudioを利用し「ui.R」と「server.R」を用意、メニューのRun Appをクリックすると作動します。
RStudioのversion 1.0.136。windows 10のR version 3.3.2で動作を確認しています。
コマンドの紹介
詳細はコマンド、各パッケージのヘルプを確認してください。
ui.Rの内容
#ui.R
#可変レイアウト
shinyUI(fluidPage(
#タイトルを指定
titlePanel("PubMedでWordCloud"),
#1行目:可変レイアウト
fluidRow(plotOutput("WordCloud", width = "100%")),
#2行目:可変レイアウト
fluidRow(
#1列目
column(2, textInput("QueryWord", "クエリ", "クエリを入力"),
textInput("GetPaper", "取得論文数", "100"),
actionButton("GoWordCloud", "ワードクラウドを作成")),
#2列目
column(10, sliderInput("CountWord", "単語出現数",
min = 1, max = 20, value = 5, step = 1))
)
)
)server.Rの内容
#server.R
#パッケージの読み込み
if (!require("easyPubMed")) {
install.packages("easyPubMed")}
if (!require("tm")) {
install.packages("tm")}
if (!require("wordcloud")) {
install.packages("wordcloud")}
if (!require("tcltk")) {
install.packages("tcltk")}
shinyServer(function(input, output) {
output$WordCloud <- renderPlot({
#GoWordCloudボタンが押されるまで動作しない
input$GoWordCloud
#isolateがポイント
isolate(
if("クエリを入力" == input$QueryWord){
}else{
#結果の取得
ALL_Result <- get_pubmed_ids(input$QueryWord)
GetResult <- fetch_pubmed_data(ALL_Result,
retmax = input$GetPaper, format = "xml")
#論文タイトルを取得
TitleData <- unlist(xpathApply(GetResult, "//ArticleTitle", xmlValue))
###テキストマイニングの設定、お好みに合わせてください#####
CorMaster <- Corpus(DataframeSource(data.frame(TitleData))) #コーパスの作成
CorMaster <- tm_map(CorMaster, stripWhitespace) #空白の削除
CorMaster <- tm_map(CorMaster, removeNumbers) #数字の削除
CorMaster <- tm_map(CorMaster, removePunctuation) #句読点の削除
CorMaster <- tm_map(CorMaster, removeWords, stopwords("english")) #and, or等の削除
TermVec <- DocumentTermMatrix(CorMaster) #タームマトリックスの集計
########
###単語解析結果をデータフレーム化#####
#単語の出現率を集計
AnalyticsAllWords <- as.data.frame(apply(TermVec, 2, sum))
AnalyticsAllWords <- cbind(rownames(AnalyticsAllWords), AnalyticsAllWords)
#除去したい単語を設定
AnalyticsAllWords <- subset(AnalyticsAllWords,
!(AnalyticsAllWords[, 1] %in% c("the", "this", "can", "thus", "these")))
########
})
#かなり強引に処理
if(exists("AnalyticsAllWords") == TRUE){
AnalyticsWords <- subset(AnalyticsAllWords, AnalyticsAllWords[, 2] >= input$CountWord)
#プロット
wordcloud(AnalyticsWords[, 1], AnalyticsWords[, 2], scale = c(8, .1),
random.order = FALSE, rot.per = .10, colors = brewer.pal(8, "Dark2"))
}else{
NULL
}
})
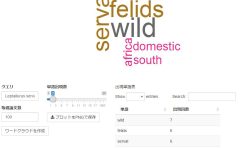
}) 出力例
・R Statics

・Leptailurus serval
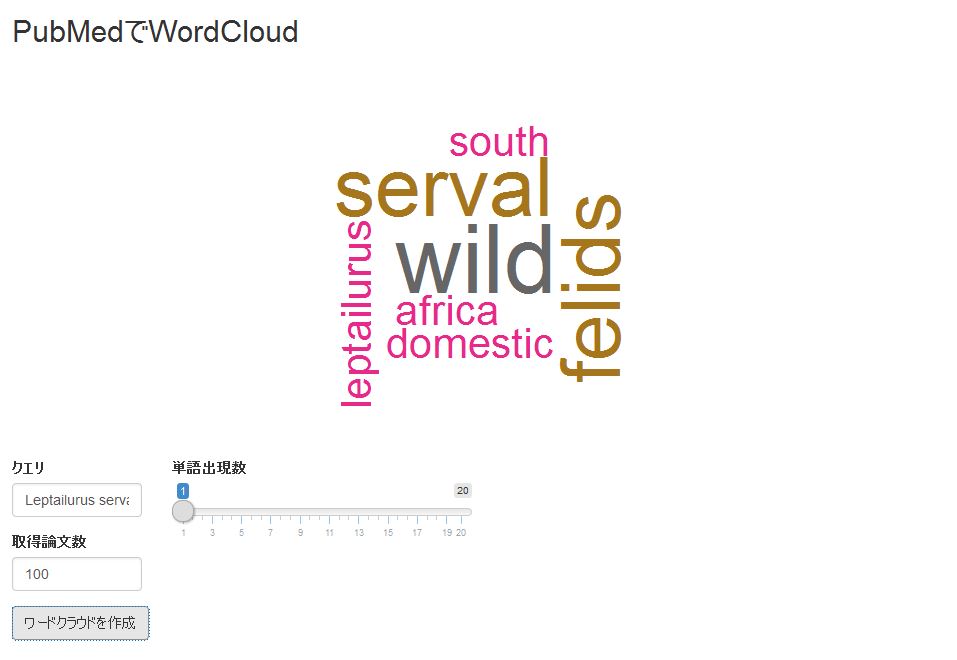
少しでも、あなたの解析が楽になりますように!!動物に関する論文を検索したことがありませんでしたが、Leptailurus servalは意外と少ないです。検索の仕方が悪いかもしれません。