画像ファイルから指定した言語でOCRが可能なパッケージの紹介です。画像の解像度により精度が変化しますが文字データの取得には十分実用的です。大変面白いパッケージです。
パッケージバージョンは5.1.0。実行コマンドはR version 4.2.2で確認しています。
パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("tesseract")実行コマンド
詳細はコマンド、各パッケージのヘルプを確認してください。
念のためtraining dataのダウンロード先を紹介します。
・training dataのダウンロード
https://tesseract-ocr.github.io/tessdoc/Data-Files
OCR処理の画像は以下の通りです。

#パッケージの読み込み
library("tesseract")
#tesseractの環境を確認:tesseract_infoコマンド
#初期状態のavailableは"eng" "osd"のみです
TessRact <- tesseract_info()
#確認
TessRact
$datapath
[1] "C:\\Users\\ユーザー名\\AppData\\Local\\tesseract5\\tesseract5\\tessdata/"
$available
[1] "eng" "osd"
$version
[1] "5.1.0"
$configs
[1] "alto" "ambigs.train" "api_config" "bigram"
[5] "box.train" "box.train.stderr" "digits" "get.images"
[9] "hocr" "inter" "kannada" "linebox"
[13] "logfile" "lstm.train" "lstmbox" "lstmdebug"
[17] "makebox" "pdf" "quiet" "rebox"
[21] "strokewidth" "tsv" "txt" "unlv"
[25] "wordstrbox"
#tessdata repositoryからtraining dataを取得:tesseract_downloadコマンド
#langオプションに目的とする言語を指定すると自動で保存されます
#なお、一度ダウンロードすると次回は実行しなくともよいです
#以下は自身でダウンロードする場合の参考です
##日本語:https://github.com/tesseract-ocr/tessdata/raw/4.00/jpn.traineddata
##ダウンロード:utils::download.fileコマンド;初期にインストールされています
##download.file(url = "https://github.com/tesseract-##ocr/tessdata/raw/4.00/jpn.traineddata",
## destfile = paste0(TessRact$datapath, "/jpn.traineddata"))
#トレーニングデータの取得と読み込み
tesseract_download(lang = "jpn")
#画像ファイルからテキストを抽出:ocrコマンド
#処理言語を指定:engineオプション
#画像ファイルを指定
OCRImg <- paste0(as.character(tcltk::tkgetOpenFile(title = "画像ファイルを選択",
filetypes = '{"画像ファイル" {".*"}}',
initialfile = "*.*")))
#OCR処理
GetOCR <- ocr(image = OCRImg,
engine = tesseract("jpn"))
#内容確認
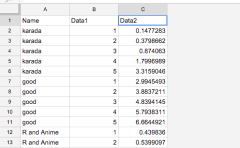
cat(GetOCR)
#以下結果;一部読み込みミスがありますが実用的です
NCBIデータベースをRかちら操作するパッケージはいくつか存在しますが、本パッケージはPubMed
データベースから情報を収集するのに特化したパッケージです。かなり簡単に情報を収集すること
が出来ます。
実行コマンドでは検索クエリに"r statistical software"を指定し、取得したデータをGoogleスプレ
ッドシートへアップロードと「xlsx]」 ファイルで保存する例を紹介します。
パッケージバージョンは2.13。実行コマンドはR version 4.2.2で確認しています。少しでも、あなたの解析が楽になりますように!!