data.frameの内容を置換するのに便利なパッケージだと思います。因子を削除するコマンドも収録されています。
パッケージバージョンは1.1.0。実行コマンドはwindows 11のR version 4.1.2で確認しています。

パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("wildcard")実行コマンド
詳細はコマンド、パッケージのヘルプを確認してください。
#パッケージの読み込み
library("wildcard")
###データ例の作成#####
set.seed(1234)
n <- 6
TestData <- data.frame(Group = factor(sample(paste0("Group", 1:5),
n, replace = TRUE)),
Data1 = round(rnorm(n), 2),
Data2 = round(rnorm(n) + rnorm(n) + rnorm(n), 2),
Data3 = sample(0:1, n, replace = TRUE),
Data4 = factor(sample(LETTERS[1:26], n,
replace = TRUE)))
#確認
TestData
# Group Data1 Data2 Data3 Data4
#1 Group4 0.04 -0.49 0 F
#2 Group2 0.11 -1.08 1 Q
#3 Group5 1.43 0.96 0 Q
#4 Group4 0.98 1.74 1 Y
#5 Group1 -0.62 -1.30 1 H
#6 Group5 -0.73 -0.31 0 Z
########
#指定内容またはルールで置換:wildcardコマンド
#データを指定:dfオプション
#指定内容:wildcardオプション
#置換内容:valuesオプション
#置換内容を全て適応:expand;TRUE;FALSEで順番に適応
wildcard(df = TestData, wildcard = "0",
values = c("ZERO", "KARADA"),
expand = TRUE, rules = NULL)
# Group Data1 Data2 Data3 Data4
#1 Group4 ZERO.ZERO4 -ZERO.49 ZERO F
#2 Group4 KARADA.KARADA4 -KARADA.49 KARADA F
#3 Group2 ZERO.11 -1.ZERO8 1 Q
#4 Group2 KARADA.11 -1.KARADA8 1 Q
#5 Group5 1.43 ZERO.96 ZERO Q
#6 Group5 1.43 KARADA.96 KARADA Q
#7 Group4 ZERO.98 1.74 1 Y
#8 Group4 KARADA.98 1.74 1 Y
#9 Group1 -ZERO.62 -1.3 1 H
#10 Group1 -KARADA.62 -1.3 1 H
#11 Group5 -ZERO.73 -ZERO.31 ZERO Z
#12 Group5 -KARADA.73 -KARADA.31 KARADA Z
#ルールで置換
#Group2が全て適応,0が順番に適応
Rules <- list(Group2 = c("G2", "G3"), "0" = c("Zero", ""))
wildcard(df = TestData, expand = c(TRUE, FALSE), rules = Rules)
# Group Data1 Data2 Data3 Data4
#1 Group4 Zero.Zero4 -Zero.49 Zero F
#2 G2 .11 -1.8 1 Q
#3 G3 Zero.11 -1.Zero8 1 Q
#4 Group5 1.43 .96 Q
#5 Group4 .98 1.74 1 Y
#6 Group1 -Zero.62 -1.3 1 H
#7 Group5 -.73 -Zero.31 Zero Z
#データ内容を行方向に繰り返す:expandrowsコマンド
#繰り返し方法の指定:typeオプション;"each","times"が指定可能
expandrows(df = TestData, n = 2, type = "times")
# Group Data1 Data2 Data3 Data4
#1 Group4 0.04 -0.49 0 F
#2 Group2 0.11 -1.08 1 Q
#3 Group5 1.43 0.96 0 Q
#4 Group4 0.98 1.74 1 Y
#5 Group1 -0.62 -1.30 1 H
#6 Group5 -0.73 -0.31 0 Z
#7 Group4 0.04 -0.49 0 F
#8 Group2 0.11 -1.08 1 Q
#9 Group5 1.43 0.96 0 Q
#10 Group4 0.98 1.74 1 Y
#11 Group1 -0.62 -1.30 1 H
#12 Group5 -0.73 -0.31 0 Z
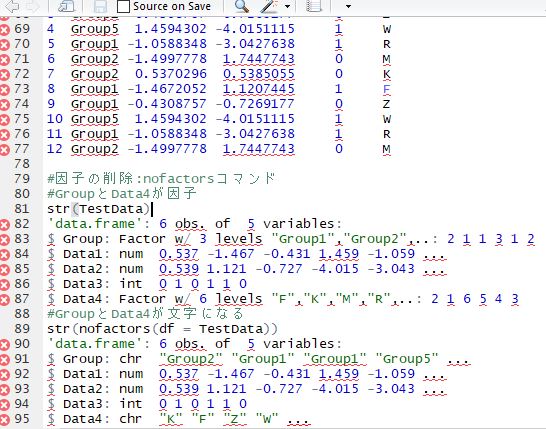
#因子の削除:nofactorsコマンド
#GroupとData4が因子
str(TestData)
#'data.frame': 6 obs. of 5 variables:
#$ Group: Factor w/ 4 levels "Group1","Group2",..: 3 2 4 3 1 4
#$ Data1: num 0.04 0.11 1.43 0.98 -0.62 -0.73
#$ Data2: num -0.49 -1.08 0.96 1.74 -1.3 -0.31
#$ Data3: int 0 1 0 1 1 0
#$ Data4: Factor w/ 5 levels "F","H","Q","Y",..: 1 3 3 4 2 5
#GroupとData4が文字になる
str(nofactors(df = TestData))
#'data.frame': 6 obs. of 5 variables:
#$ Group: chr "Group4" "Group2" "Group5" "Group4" ...
#$ Data1: num 0.04 0.11 1.43 0.98 -0.62 -0.73
#$ Data2: num -0.49 -1.08 0.96 1.74 -1.3 -0.31
#$ Data3: int 0 1 0 1 1 0
#$ Data4: chr "F" "Q" "Q" "Y" ...少しでも、あなたの解析が楽になりますように!!