RStudioのR MarkDownのPDFで日本語を扱う環境設定の覚書です。また、PDF内でggplot2に日本語を適応するコマンド例とRmdファイルを紹介します。
RStudioで図のプロットの日本語が文字化けもしくは表示されない場合は下記記事が参考になるかもしれません。
実行コマンドはRStudioのRStudio Desktop 2021.09.2+382、windows 11のR version 4.1.2で確認しています。
必要なパッケージのインストール
下記コマンドをRStudioで実行してください。
#パッケージのインストール
install.packages(c("tinytex", "rmarkdown", "bitops",
"caTools", "rprojroot", "tidyverse"))TinyTeXとIPAフォントのインストール
tinytexパッケージはPDFで日本語を扱う環境を整えるのに便利なパッケージです。詳細はパッケージのヘルプを確認してください。
IPAフォントの詳細は下記リンクを参照してください。
・独立行政法人情報処理推進機構
https://ipafont.ipa.go.jp/old/ipafont/download.html
#TinyTeXのインストール
tinytex:::install_prebuilt()
#もしくは
#tinytex::install_tinytex()
#ipaフォントのインストール
#C:\Users\"ユーザー名"\AppData\Roaming\TinyTeX\texmf-dist\fonts\truetype\public\ipaex
#にフォントファイルがインストールされます
tinytex::tlmgr_install("ipaex")ggplot2で日本語を扱うコマンド例
詳細はコマンド、Rmdファイル(エンコード:UTF-8)、パッケージヘルプを確認してください。
---
title: "テスト"
date: "2022/1/23"
output:
pdf_document:
latex_engine: xelatex
highlight: "zenburn"
mainfont: ipaexg.ttf
---
# ggplot2での日本語設定
#以下を設定する。一度設定すればOK。チャンクにinclude=FALSEを追記すると良い。
```{r setup, include=TRUE}
knitr::opts_chunk$set(dev = "cairo_pdf", dev.args = list(family = "ipaexg"))
# パッケージの読み込み
library("tidyverse")
# データ例の作成
n <- 100
TestData <- data.frame(Group = sample(paste0("グループ", 1:5),
n, replace = TRUE),
Data = sample(c("か", "ら", "だ", "に", "い", "い",
"も","の"), n, replace = TRUE))
```
# プロット
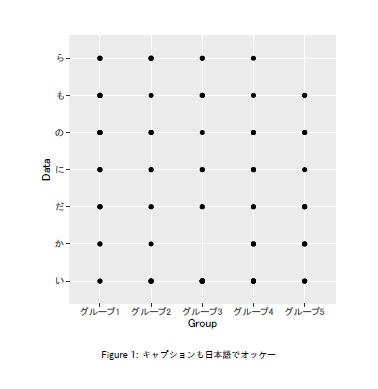
```{r, fig.cap="キャプションも日本語でオッケー", include=TRUE, fig.width=4, fig.height=4}
ggplot(TestData, aes(x = Group, y = Data)) + geom_point()
```出力ファイル
プロット部分を切り出した画像と出力結果のPDFを紹介します。
少しでも、あなたの解析が楽になりますように!!