文字列操作と検索「grep」と置換「gsub」コマンドがあります。これらのコマンドだけでも十分な作業ができますが、念のため「stringr」パッケージを簡単に紹介したいと思います。
Rで解析:文字列操作と検索「grep」と置換「gsub」コマンドの紹介は以下の記事を参考にしてください。

パッケージバージョンは1.4.0。windows 10のR version 4.1.1で動作を確認しています。
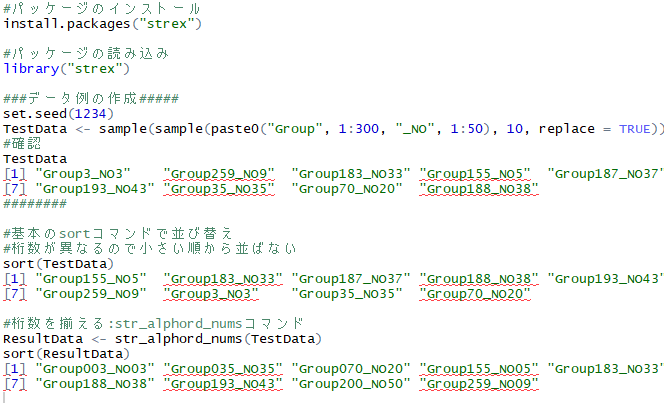
パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("stringr")コマンドの紹介
下記コマンドを実行してください。詳細は各パッケージのヘルプを確認してください。
#パッケージの読み込み
library("stringr")
#データ例作成に必要なパッケージ
library("stringi")
#指定パターンから指定の長さで文字列を作成
#stringrパッケージのstri_rand_stringsコマンド
#生成数を指定:nオプション
#文字列の長さを指定:lengthオプション
#パターンを指定:patternオプション
#stri_rand_strings(n = 3, length = 4, pattern = "[a-zあ-ん]")
#[1] "るばGガ" "iニョあ" "tVヲっ"
###データ例の作成#####
set.seed(50)
n <- 50
TestData <- data.frame(paste0("Group", formatC(1:n, width = 2, flag = "0")),
matrix(stri_rand_strings(n = n^2, length = 4,
pattern = "[a-zA-Z]"), n, n))
colnames(TestData) <- c("Group", paste0("Word", formatC(1:n, width = 2, flag = "0")))
########
#文字列の結合:str_cコマンド
#任意の文字で結合:sepオプション
Test_join <- str_c(TestData$Group, TestData$Word02, sep = "_")
head(Test_join)
[1] "Group01_DgaX" "Group02_bJhO" "Group03_sWai" "Group04_GAvQ"
[5] "Group05_EbAs" "Group06_sGKU"
#文字列の分割:str_splitコマンド
#任意の文字で分割:patternオプション
#行列で出力:simplifyオプション:FALSEでlist
Test_split <- str_split(string = Test_join,
pattern = "_",
simplify = "TRUE")
head(Test_split)
[,1] [,2]
[1,] "Group01" "DgaX"
[2,] "Group02" "bJhO"
[3,] "Group03" "sWai"
[4,] "Group04" "GAvQ"
[5,] "Group05" "EbAs"
[6,] "Group06" "sGKU"
#特定文字を含む文字列を検索:str_countコマンド
Test_count <- str_count(Test_join, pattern = "a")
head(Test_count)
[1] 1 0 1 0 0 0
###大文字小文字関係なく検索#####
#どのコマンドでも適応が可能です
#collコマンドを利用する,文字コードレベルであればfixedコマンド
Coll_Test_count <- str_count(Test_join,
pattern = coll(pattern = "a", ignore_case = TRUE))
head(Coll_Test_count)
[1] 1 0 1 1 1 0
#特定文字を含む文字列内での全ての位置を検索:str_locate_allコマンド
#str_locateコマンドもあります
Locate_Test_count <- str_locate_all(Test_join,
pattern = coll(pattern = "a", ignore_case = TRUE))
head(Coll_Test_count)
[[1]]
start end
[1,] 11 11
[[2]]
start end
[[3]]
start end
[1,] 11 11
#位置を確認しながら文字列を抽出:str_extractコマンド
#str_extract_allコマンドもあります
Extract_Test_count <- str_extract(Test_join,
pattern = coll(pattern = "a", ignore_case = TRUE))
head(Extract_Test_count)
[1] "a" NA "a" "A" "A" NA
#指定した文字を含む文字列を抽出:str_subsetコマンド
Subset_Test_count <- str_subset(Test_join,
pattern = coll(pattern = "a", ignore_case = TRUE))
head(Subset_Test_count)
[1] "Group01_DgaX" "Group03_sWai" "Group04_GAvQ" "Group05_EbAs" "Group14_Qagw"
[6] "Group19_LAOV"
#文字列の置換:str_replaceコマンド
#str_replace_allコマンドもあります
#置き換え文字の指定:replacementオプション
Replace_Test_count <- str_replace_all(Test_join,
pattern = coll(pattern = "a", ignore_case = TRUE),
replacement = "c")
head(Replace_Test_count)
[1] "Group01_DgcX" "Group02_bJhO" "Group03_sWci" "Group04_GcvQ" "Group05_Ebcs" "Group06_sGKU"少しでも、あなたのウェブや実験の解析が楽になりますように!!