データにGroup番号やGroup内での出現順、そして、行位置の列を「tidyverse」パッケージまたは「dplyr」パッケージを利用して付与する方法です。非常に簡単に付与することができます。ポイントは「group_by」コマンドで基準となるGroupの列を指定することです。
なお、紹介するコマンドは「mutate」コマンドだけでなく、「summarise」コマンドなどと組み合わせて使用することが可能です。
「dplyr」パッケージは「tidyverse」パッケージに含まれています。実行コマンドでは「tidyverse」パッケージを利用しています。
パッケージバージョンは2.0.0、実行コマンドはR version 4.3.1で確認しています。
パッケージのインストール
下記、コマンドを実行してください。
#パッケージのインストール
install.packages("tidyverse")実行コマンド
詳細はコメント、パッケージのヘルプを確認してください。
#パッケージの読込み
library("tidyverse")
###データ例の作成#####
set.seed(1234)
TestData <- tibble(Group = sample(LETTERS[1:4], size = 8, replace = TRUE),
Data_1 = rep(1:4, time = 2),
Data_2 = rep(5:8, time = 2)) %>%
group_by(Group)
#確認
#4つのGroupが指定されている
TestData
# A tibble: 8 × 3
# Groups: Group [4]
# Group Data_1 Data_2
#<chr> <int> <int>
#1 D 1 5
#2 D 2 6
#3 B 3 7
#4 B 4 8
#5 A 1 5
#6 D 2 6
#7 C 3 7
#8 A 4 8
#######
#Group番号の列を付与する:dplyr::cur_group_idコマンド
TestData %>%
mutate(Group_No = cur_group_id(),
.before = Group) %>%
arrange(Group_No)
# A tibble: 8 × 4
# Groups: Group [4]
# Group_No Group Data_1 Data_2
# <int> <chr> <int> <int>
#1 1 A 1 5
#2 1 A 4 8
#3 2 B 3 7
#4 2 B 4 8
#5 3 C 3 7
#6 4 D 1 5
#7 4 D 2 6
#8 4 D 2 6
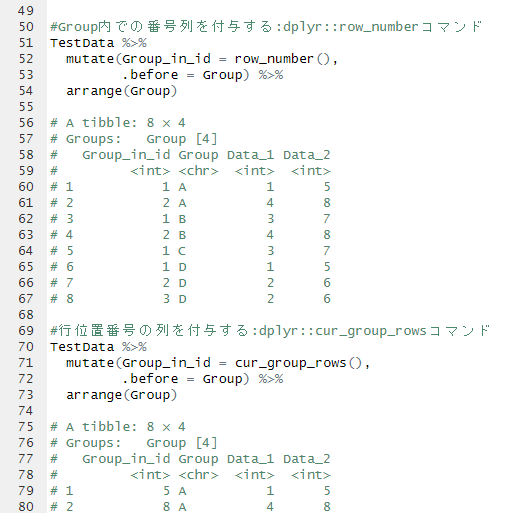
#Group内での出現順の列を付与する:dplyr::row_numberコマンド
TestData %>%
mutate(Group_in_id = row_number(),
.before = Group) %>%
arrange(Group)
# A tibble: 8 × 4
# Groups: Group [4]
# Group_in_id Group Data_1 Data_2
# <int> <chr> <int> <int>
#1 1 A 1 5
#2 2 A 4 8
#3 1 B 3 7
#4 2 B 4 8
#5 1 C 3 7
#6 1 D 1 5
#7 2 D 2 6
#8 3 D 2 6
#行位置の列を付与する:dplyr::cur_group_rowsコマンド
TestData %>%
mutate(Group_in_id = cur_group_rows(),
.before = Group) %>%
arrange(Group)
# A tibble: 8 × 4
# Groups: Group [4]
# Group_in_id Group Data_1 Data_2
# <int> <chr> <int> <int>
#1 5 A 1 5
#2 8 A 4 8
#3 3 B 3 7
#4 4 B 4 8
#5 7 C 3 7
#6 1 D 1 5
#7 2 D 2 6
#8 6 D 2 6少しでも、あなたの解析が楽になりますように!!