データ分析はデータの特性を把握することが重要です。しかし、データの前処理や探索的データ分析は時間と手間がかかります。「dataProfilerR」パッケージは、そんな手間のかかる作業を簡単におこなえるパッケージです。
列型推定、分布の要約統計量、正規性検定、外れ値の検出、相関やカテゴリー別分析などのコマンドが収録されています。
また、解析結果はHTMLレポートとして出力することも可能です。本パッケージの利用で、効率的にデータの特性を把握が可能となり、時間と手間を減らせるのではないかと考えます。
パッケージバージョンは0.2.1。Windows 11 x64 (build 26200)のR version 4.6.0で確認しています。
<おすすめのRに関する書籍です>

Rによる統計データ解析 | 小池 祐太, 村田 昇, 吉田 朋広 |本 | 通販 | Amazon
Amazonで小池 祐太, 村田 昇, 吉田 朋広のRによる統計データ解析。アマゾンならポイント還元本が多数。小池 祐太, 村田 昇, 吉田 朋広作品ほか、お急ぎ便対象商品は当日お届けも可能。またRに…
www.amazon.co.jp
パッケージのインストール
下記コマンドを実行してください。
# パッケージのインストール
install.packages("dataProfilerR")
# パッケージの読み込み
library("dataProfilerR")コマンド例
詳細はコメント、パッケージのヘルプを確認してください。
データの傾向を取得する
# データの傾向を取得:profile_dataコマンド
# dfオプション:データ設定
# dataset_nameオプション:データラベル;初期値NULL
# build_plotsオプション:プロットの可否;初期値TRUE
# distributionsオプション:分布図のプロット可否;初期値TRUE
# normalityオプション:正規性検定の可否;初期値TRUE
# outlier_methodオプション:異常値の検出計算方法;初期値"iqr"
# cor_methodオプション:相関係数の計算方法;初期値c("pearson", "spearman")
# verboseオプション:処理状況を表示;初期値FALSE
# データの準備
p <- profile_data(iris)
summary(p)
データの概要を可視化する
データの傾向の可視化は、profile_dataコマンドで処理したオブジェクトをplotコマンドで処理する際にwhichオプション(作図の種類)、columnオプション(対象の列名)でおこないます。
# プロファイルデータの可視化
# 相関をプロット
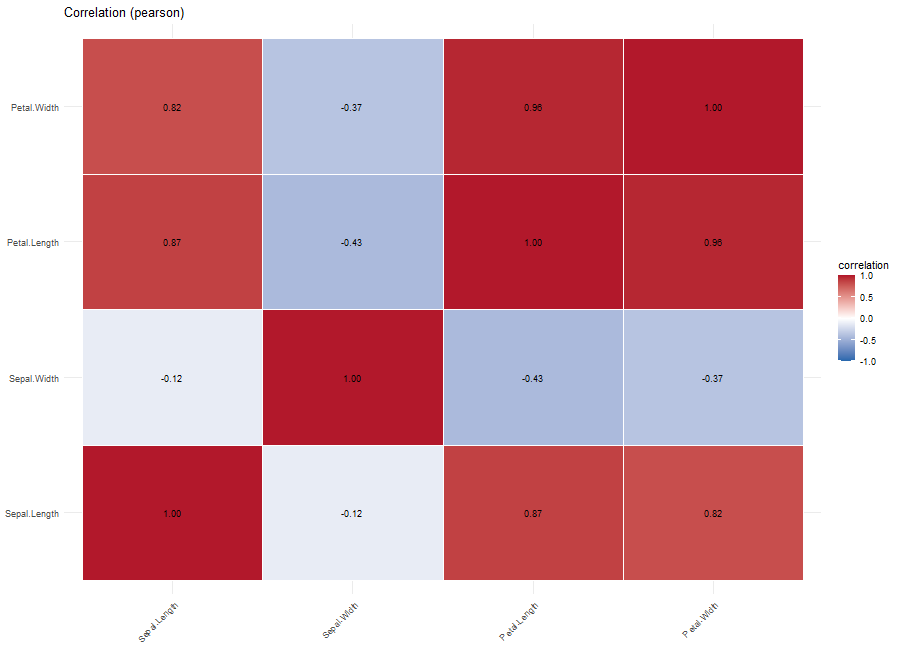
plot(p, which = "correlation")
# 欠損値をプロット
plot(p, which = "missing")
# 分布をプロット
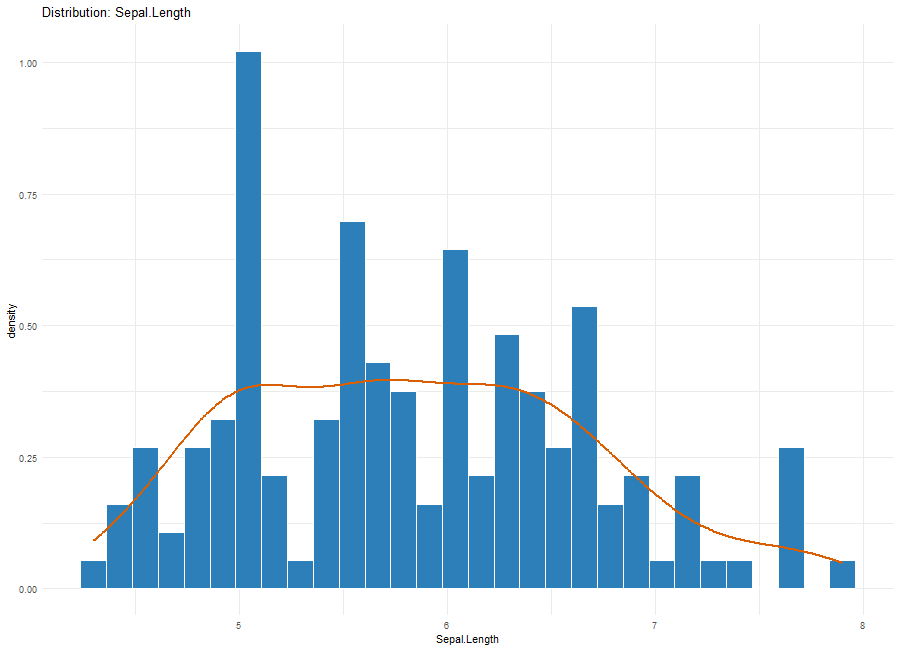
plot(p, which = "distribution", column = "Sepal.Length")・相関をプロット:which = “correlation”
・欠損値をプロット:which = “missing”
・分布をプロット:which = “distribution”, column = “Sepal.Length”
<おすすめのRに関する書籍です>
Rによる統計データ解析 | 小池 祐太, 村田 昇, 吉田 朋広 |本 | 通販 | Amazon
Amazonで小池 祐太, 村田 昇, 吉田 朋広のRによる統計データ解析。アマゾンならポイント還元本が多数。小池 祐太, 村田 昇, 吉田 朋広作品ほか、お急ぎ便対象商品は当日お届けも可能。またRに…
www.amazon.co.jp
データの傾向をhtmlで出力する
コマンド実行後、htmlファイルの保存先が表示されます。
# profile_dataの処理結果をブラウザで表示:reportコマンド
# output_fileオプション:保存ファイル名を設定
# titleオプション:結果タイトルを設定
# quietオプション:処理状況の表示;初期値TRUE
report(p, output_file = "dataProfilerR_report.html",
title = "テスト", quiet = TRUE)
Report written to C:/dataProfilerR_report.html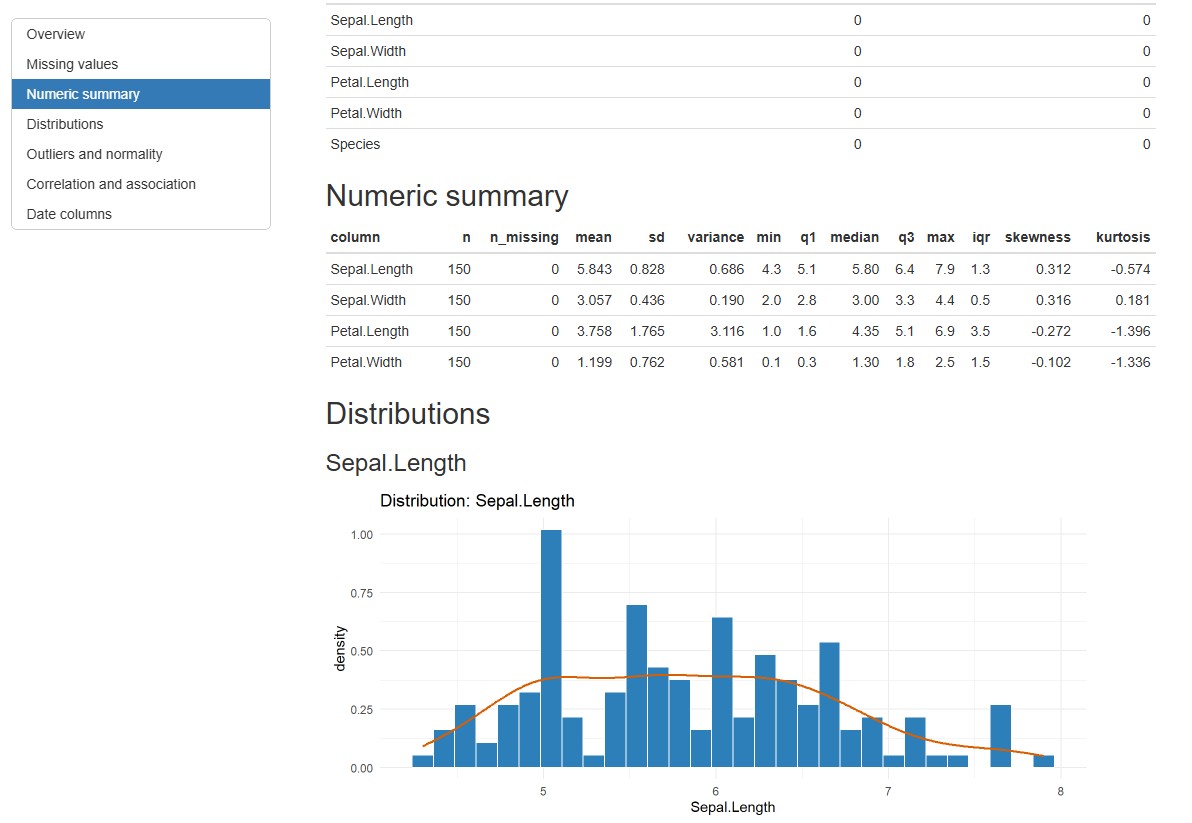
列の型を推測する
# 列の型を推測する:infer_column_typesコマンド
# text_min_avg_charsオプション:カテゴリ変数として認識する文字列の長さ;初期値50
# text_unique_ratioオプション:テキストデータとして扱うユニークな値の割合;初期値0.8
infer_column_types(data.frame(a = 1:3, b = c("x", "y", "z"),
d = Sys.Date() + 0:2))
a b d
"integer" "categorical" "date" 正規性検定を実行する
# 正規性検定を実行:normality_testsコマンド
# dfオプション:データフレーム
# typesオプション:列のデータ型の指定;初期値NULL
# alphaオプション:有意水準;初期値0.05
normality_tests(iris)
column n_used shapiro_W shapiro_p ad_A ad_p normal
1 Sepal.Length 150 0.9760903 1.018116e-02 NA NA FALSE
2 Sepal.Width 150 0.9849179 1.011543e-01 NA NA TRUE
3 Petal.Length 150 0.8762681 7.412263e-10 NA NA FALSE
4 Petal.Width 150 0.9018349 1.680465e-08 NA NA FALSEボックスプロットで各列の分布を可視化
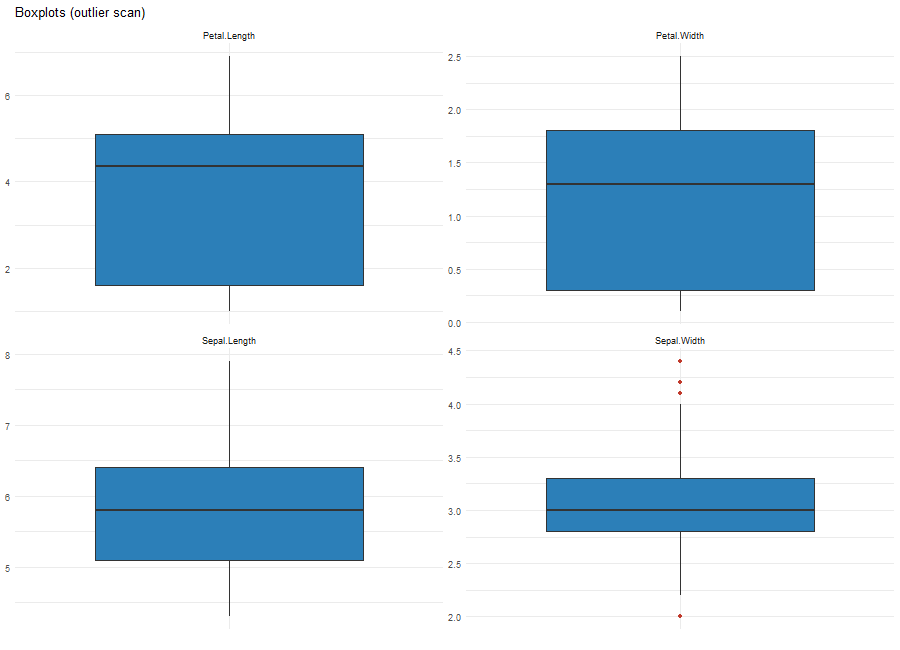
# 箱ひげ図のプロット:plot_boxplotコマンド
# dfオプション:データフレーム。
plot_boxplots(iris)・箱ひげ図のプロット:plot_boxplotコマンド
単一の列の分布をプロット
# 分布のプロット:plot_distributionコマンド
# dfオプション:データフレーム。
# columnオプション:プロットする列名。
# binsオプション:数値列のヒストグラムの区間。;初期値30
# max_levelsオプション:カテゴリ列の表示上限。;初期値20
plot_distribution(iris, column = "Sepal.Length", bins = 30, max_levels = 20)
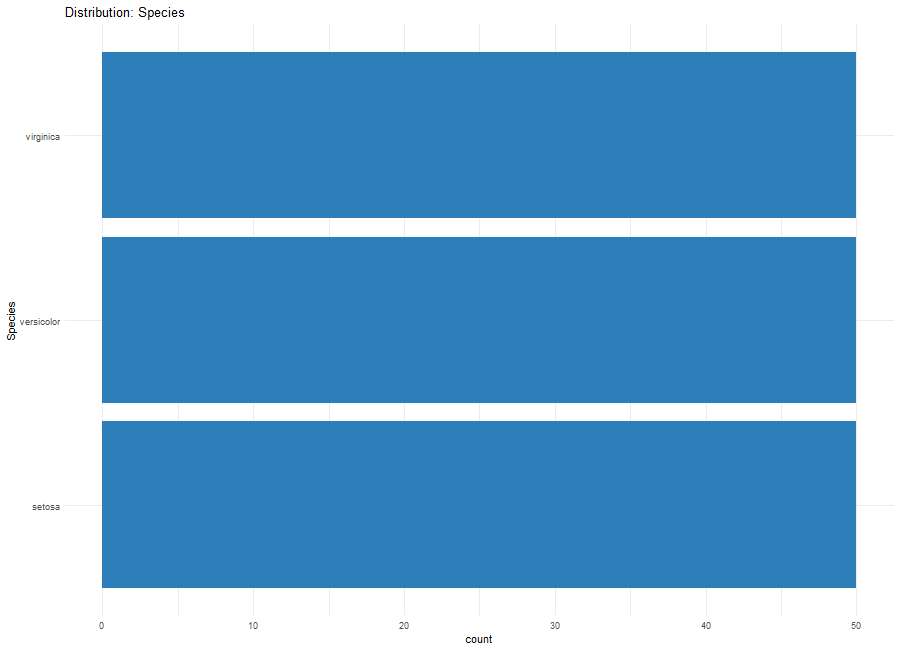
plot_distribution(iris, "Species")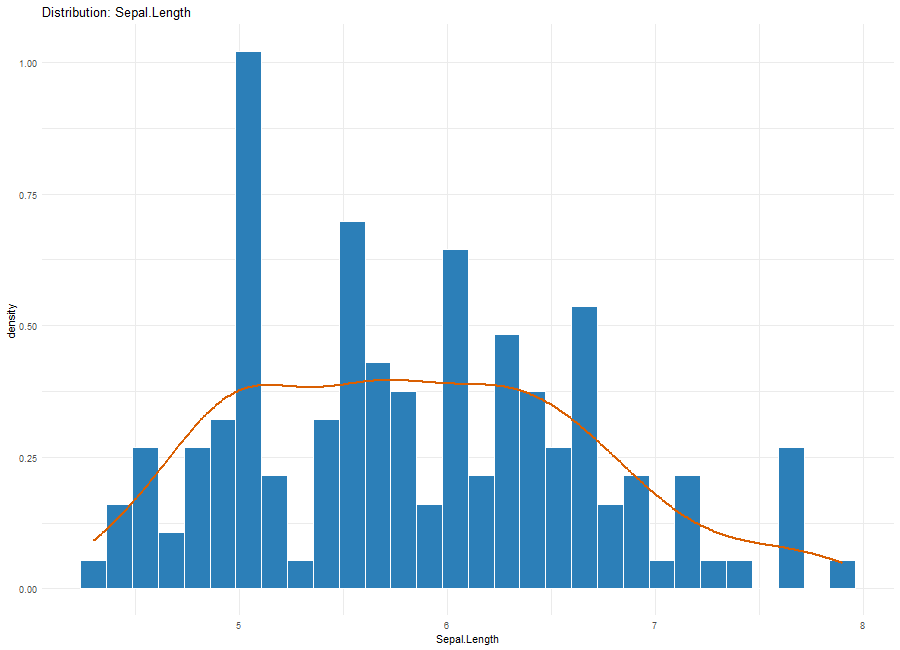
<おすすめのRに関する書籍です>
Rによる統計データ解析 | 小池 祐太, 村田 昇, 吉田 朋広 |本 | 通販 | Amazon
Amazonで小池 祐太, 村田 昇, 吉田 朋広のRによる統計データ解析。アマゾンならポイント還元本が多数。小池 祐太, 村田 昇, 吉田 朋広作品ほか、お急ぎ便対象商品は当日お届けも可能。またRに…
www.amazon.co.jp
散布図行列をプロット
# ペアプロットの生成:plot_pairsコマンド
# dfオプション:データフレーム。
# columnsオプション:含める数値列の指定。;初期値NULL
# max_colsオプション:含める列数の上限。;初期値5
plot_pairs(iris, c("Sepal.Length", "Sepal.Width", "Petal.Length"),
columns = NULL, max_cols = 5)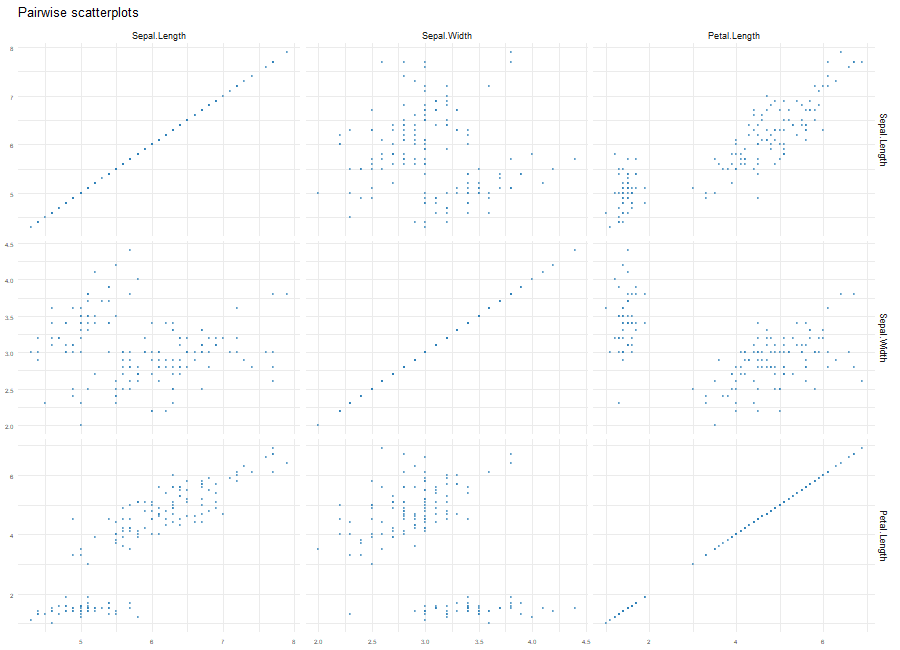
この記事が誰かの役に立ちますように。