ファイルをGUIで楽々読み込むパッケージの紹介です。対応ファイルは「csv、csv2、tsv、txt、xls、xlsx、json、html、htm、php、pdf、doc、docx、rtf、RData、Rda、RDS、sav(SPSS)、por、sas7bdat、sas7bcat、dta、xpt、mbox、Rmd」の25種類です。非常に利用が簡単なパッケージです。
なお、ファイル名および内容に日本語が含まれていても問題ありません。
パッケージバージョンは2.1.0。実行コマンドはwindows 11のR version 4.3.1で確認しています。
パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("ezpickr")
#もしくはR 4.3.1の場合
remotes::install_github('jooyoungseo/mboxr')
remotes::install_github('trinker/textreadr')
remotes::install_github('jooyoungseo/ezpickr')コマンドの紹介
詳細はコマンド、パッケージのヘルプを確認してください。
#パッケージの読み込み
library("ezpickr")
###データ例の作成#####
set.seed(1234)
n <- 10
TestData <- data.frame(ID = 1:n,
Group = sample(c("A", "テスト", "C"),
n, replace = TRUE),
Time_A = rnorm(n),
Time_B = rnorm(n))
#ForImpパッケージを利用
if(!require("ForImp", quietly = TRUE)){
install.packages("ForImp");require("ForImp")
}
#欠損値を代入
TestData[, 3:4] <- missingmat2(TestData[, 3:4], missing = 10)
#保存場所を指定してxlsxで出力
#openxlsxパッケージを利用
if(!require("openxlsx", quietly = TRUE)){
install.packages("openxlsx");require("openxlsx")
}
#保存
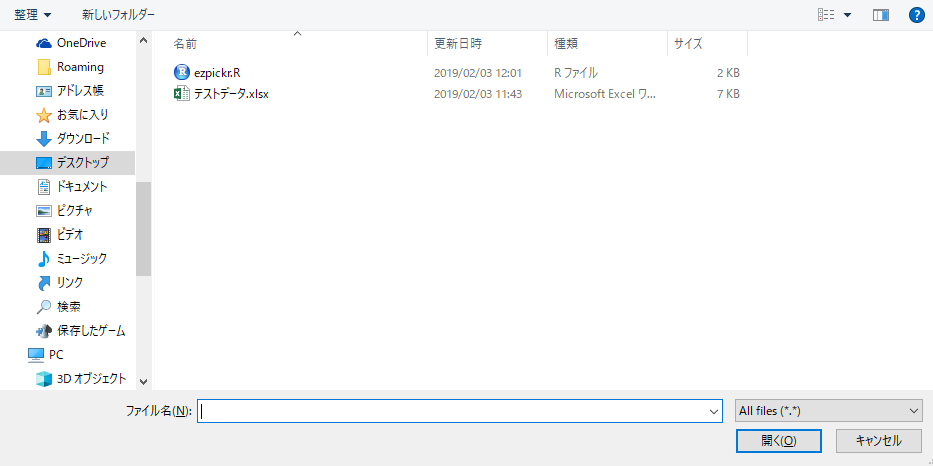
setwd(dir = choose.dir(caption = "保存場所を指定"))
write.xlsx(TestData, "TestData.xlsx")
#######
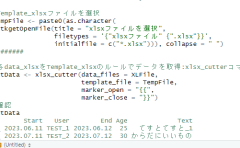
#ダイアログからファイルを読み込む:pickコマンド
#読み込み可能なファイル形式:
#csv, csv2, tsv, txt, xls, xlsx, json, html, htm, php, pdf,
#doc, docx, rtf, RData, Rda, RDS, sav(SPSS), por, sas7bdat,
#sas7bcat, dta, xpt, mbox, Rmd
#データ例を読み込み
ReadData <- pick()
#確認
ReadData
# A tibble: 10 x 4
ID Group Time_A Time_B
<dbl> <chr> <dbl> <dbl>
1 1 テスト NA 0.705
2 2 テスト NA -0.647
3 3 A NA 0.868
4 4 C -0.517 NA
5 5 A NA 0.310
6 6 A 0.880 NA
7 7 テスト 1.37 NA
8 8 テスト -1.69 NA
9 9 C -0.627 NA
10 10 テスト NA 0.0114実行例
少しでも、あなたの解析が楽になりますように!!