今回は、データの重複排除と重複数のカウント方法を紹介します。なお、近年のパソコンは能力が向上しているのでコードの最適化よりもいかにストレスがからだにかからない、からだにいいコードです。皆様の作業が楽になりますように。
必要なもの
・ R(ダウンロード先はこの記事を参照ください。)
・ library XLConnect(ダウンロード先はこの記事を参照ください。)
紹介するコマンド
・ unique() : 重複削除
・ table():重複数のカウント
作業方法
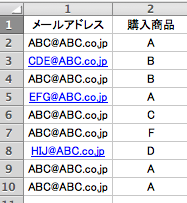
下記のデータを例にしています。
Rを立ち上げ、コードを実行します。
まずは、データを読み込む。
###ライブラリの読み込み#####
library("XLConnect")
library("tcltk")
########
###データの読み込み#####
selectABook <- paste(as.character(tkgetOpenFile(title = "エクセルファイルを選択",
filetypes = '{"エクセルファイル" {".xls" ".xlsx"}}')), sep = "", collapse =" ")
AnaData <- readWorksheet(loadWorkbook(selectABook), sheet = 1)
########例えばメールアドレスを重複せずに取得する。
unique(AnaData[, 1])
"ABC@ABC.co.jp" "CDE@ABC.co.jp" "EFG@ABC.co.jp" "HIJ@ABC.co.jp"例えばメールアドレスの出現数を取得する。
table(AnaData[, 1])そして、上記のコマンドを組み合わせるとメールアドレス別の購入商品をまとめたりする事ができます。
UniqueData <- unique(AnaData[,1]) #メールアドレスの重複削除
FinalData <- NULL #出力データの格納用
for(n in 1:length(UniqueData)){
orderProduct <- subset(AnaData, AnaData[,1] == UniqueData[n])[,2] #購入商品の抽出
orderProduct <- paste(orderProduct, collapse = ",") #購入商品の整理
OrderProducts <- cbind(UniqueData[n], orderProduct) #メールアドレスと商品名の合体
FinalData <- rbind(FinalData, OrderProducts) #データの格納
}
colnames(FinalData) <- c("メールアドレス", "購入商品") #データの整え
FinalData #データの表示
メールアドレス 購入商品
[1,] "ABC@ABC.co.jp" "A,B,C,F,A,A"
[2,] "CDE@ABC.co.jp" "B"
[3,] "EFG@ABC.co.jp" "A"
[4,] "HIJ@ABC.co.jp" "D"後は、適時エクセルにデータを変換したりしています。エクセルへの変換はこの記事を参照ください。