“assignコマンド”を利用した「規則的に変数名(オブジェクト)を作成し値(データ)を代入する方法」と”eval(parse(text = “命令内容”))コマンド”を利用した「文字列(例えば”TEST”のようにダブルクォーテーションで囲った文字)でRに命令する方法」を紹介します。forコマンドなどの繰り返し処理時に役に立つのではと思います。
コマンドはR version 3.4.2で確認しています。なお、新たなパッケージのインストールは必要ありません。
規則的に変数名を作成し値を代入する方法
“assignコマンド”を利用しています。ベクトルとデータフレームの作成を紹介します。詳細はコメントを確認してください。なお、データは”sample関数”で作成していますので実行のたびに内容が異なります。
#ベクトルの作成
#Test1から5のオブジェクトを作成しデータを代入
for( i in seq(5)){
assign(paste("Test", i, sep = ""),
sample(10:100, size = 10, replace = TRUE),
env = .GlobalEnv)
}
#もちろん、データフレームも可能です
#TestDF1から5のオブジェクトを作成しデータを代入
for( i in seq(5)){
assign(paste("TestDF", i, sep = ""),
data.frame(TEST1 = sample(10:100, size = 10, replace = TRUE),
TEST2 = sample(200:300, size = 10, replace = TRUE)),
env = .GlobalEnv)
}文字列でRに命令する方法
“eval(parse(text = “命令内容”))コマンド”を利用しています。データ内容の表示と散布図の出力例を紹介します。なお、データは「規則的に変数名を作成し値を代入する方法」で作成したものです。
紹介しませんが、処理に時間がかかる時は、処理速度が速い”eval(substitute(do.call()))コマンド”の利用を検討してはいかがでしょう。
#eval(parse(text = "命令内容"))コマンド
#作成したTest1からの内容をcatコマンドを使用してラベルを付けて表示する
for( i in seq(5)){
cat(eval(parse(text = paste("Test", i, sep = ""))),
labels = paste("Test", i, ":", sep = ""), fill = TRUE)
}
Test1: 23 48 81 18 74 59 75 49 54 14
Test2: 28 35 16 66 29 79 88 66 58 67
Test3: 61 70 88 22 27 17 58 34 87 16
Test4: 86 77 60 41 47 73 57 41 10 43
Test5: 51 63 45 25 46 65 43 23 67 88
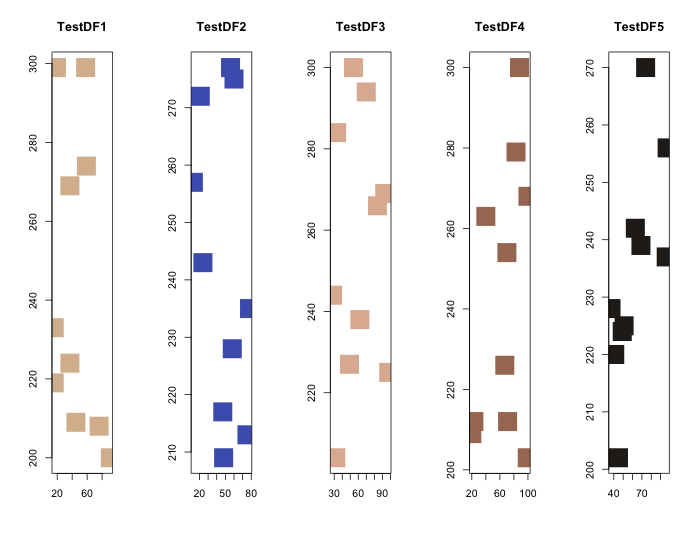
#TestDF1から5を散布図でプロット
layout(matrix(seq(5), rep(1, 5)), 1, 5)
ColSet <- c("#d9bb9c", "#4b61ba", "#deb7a0", "#a87963", "#28231e")
for( i in seq(5)){
plot(eval(parse(text = paste("TestDF", i, "[, 1]", sep = ""))),
eval(parse(text = paste("TestDF", i, "[, 2]", sep = ""))),
xlab = "", ylab = "", main = paste("TestDF", i, sep = ""),
col = ColSet[i], pch = 15, cex = 4)
}散布図の出力例
少しでも、あなたのウェブや実験の解析が楽になりますように!!