記述統計はデータをまとめ、統計量を計算し傾向や性質を理解する重要な作業です。記述統計にはデータをまとめる多くの手法がありますが、まずはデータの出現数(分布)を把握することが重要かと思います。分布を把握することでデータの入力ミス等に気がつくこともあります。
しかし、市販の統計ソフトなどでデータの分布を把握する操作はやや煩雑で、目的にあった出力を得るためにSPSSなどではシンタックスを作成することもあります。その点、Rは自由度が高いので解析作業が非常に楽です。
これら作業を軽減できるかもしれない「descr」パッケージの紹介します。本パッケージではデータの分布をクロステーブル、グラフで表示するだけでなく、「Rで処理したデータをSPSSで再現しSPSSフォーマットで保存する」シンタックスを出力するコマンドが収録されています。本パッケージの最大の特徴かと思います。
まだまだ、大学では論文投稿などの関係からSPSSを利用されている方が多いと思います。RからSPSSへのデータ移行が楽になります。ぜひ、パッケージのコマンドを活用ください。
なお、Rで作成した20*30000のデータをシンタックスで再現することが出来ました。ただし、シンタックスを利用する際には「データが記述されたテキストファイルの保存場所」に注意してください。正しい場所にテキストファイルを保存しないとエラーになります。正しい保存場所はSPSSのエラーを確認してください。また、データラベルには日本語も使用可能です。日本語が含まれている場合はダブルクリックでシンタックスファイルを開くのではなく、SPSSのメニューよりファイル、シンタックス、エンコードにUTF-8を選択してください。
パッケージのバージョンは1.1.5。実行コマンドはwindows 11のR version 4.1.2で確認しています。
パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("descr")実行コマンドの紹介
詳細はコマンドまたはパッケージヘルプを確認してください。
#パッケージの読み込み
library("descr")
#####準備#####################
#データ例の作成
set.seed(12345)
TestData <- data.frame(Data1 = sample(paste0("Group", 1:2), 40, replace = TRUE),
Data2 = sample(paste0("Group", 1:2), 40, replace = TRUE))
##############################
#データフレームの内容を再現するspssシンタックスとRコマンド,データ内容を
#作業フォルダに出力:data.frame2txtコマンド
#SPSSでspssシンタックスを実行する際は「datafile = "TestData.txt"」の
#保存場所に注意してください,出力されるspssシンタックスは「/FILE='TestData.txt'」です
#各オプションは保存ファイル名の指定に使用します
data.frame2txt(TestData, datafile = "TestData.txt", r.codefile = "TestData.R",
sps.codefile = "TestData.sps", df.name = "TestData")
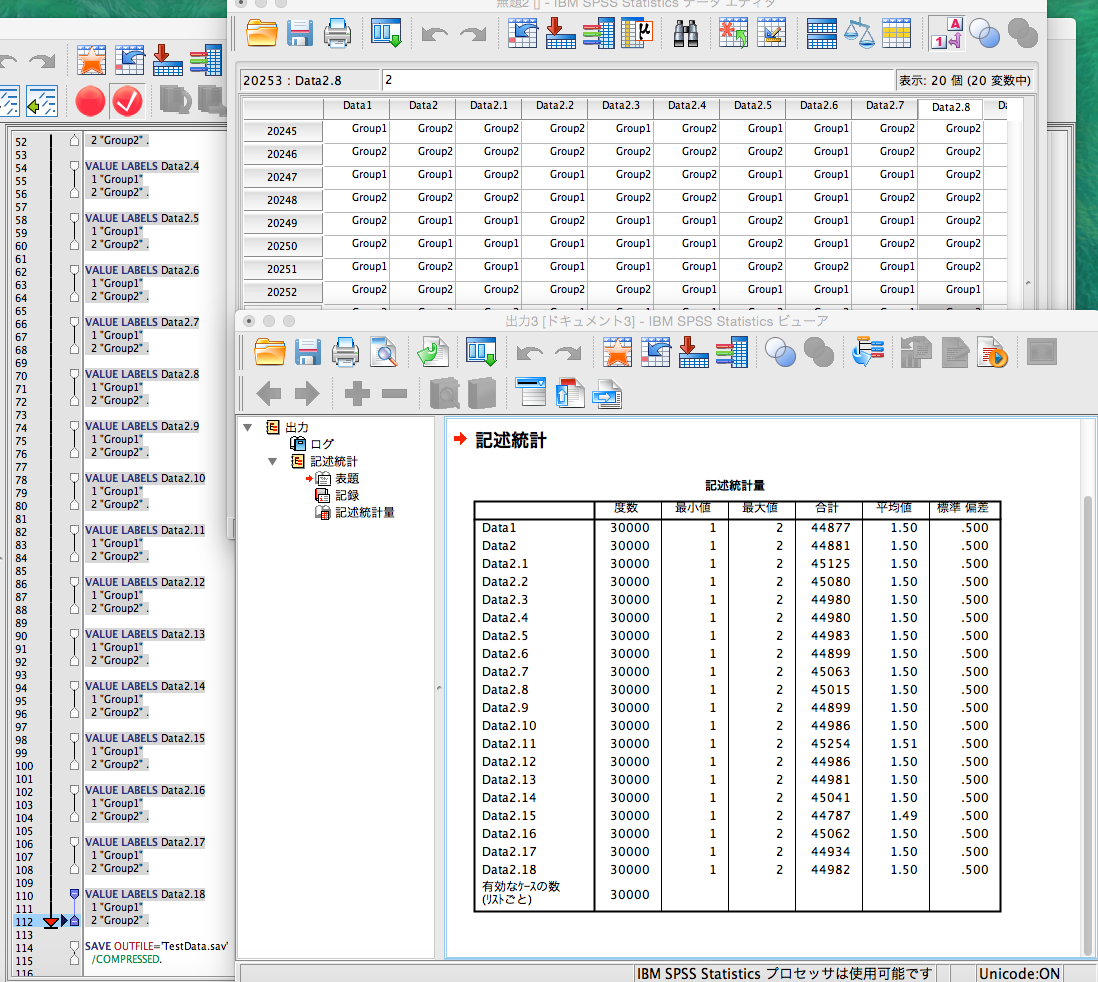
#データをクロステーブルに集計:CrossTableコマンド
#出力される表内の数字はCell Contentsを参照してください
PlotCT <- CrossTable(TestData[, 1], TestData[, 2], drop.levels = TRUE,
dnn = c(colnames(TestData[1]), colnames(TestData[2])))
#出現数をグラフで表示
plot(PlotCT)
#出現数をテーブルで表示
PlotCT
#Cell Contents
#|-------------------------|
#| N |
#| Chi-square contribution |
#| N / Row Total |
#| N / Col Total |
#| N / Table Total |
#|-------------------------|
#=================================
#Data2
#Data1 Group1 Group2 Total
#---------------------------------
# Group1 6 6 12
# 0.117 0.159
# 0.500 0.500 0.300
# 0.261 0.353
# 0.150 0.150
#---------------------------------
# Group2 17 11 28
# 0.050 0.068
# 0.607 0.393 0.700
# 0.739 0.647
# 0.425 0.275
#---------------------------------
# Total 23 17 40
# 0.575 0.425
#=================================
#データの要約を表示:descrコマンド
descr(TestData)
Data1
Length Class Mode
40 character character
Data2
Length Class Mode
40 character character
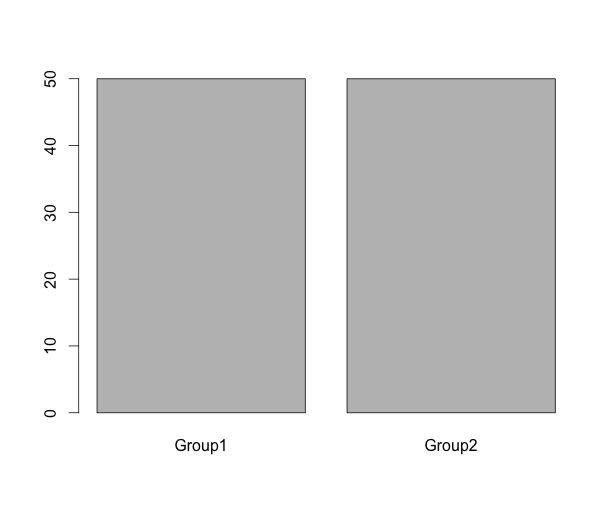
#データの出現率を表示:freqコマンド
#グラフも合わせて出力されます
freq(TestData[, 1], y.axis = "percent")
#TestData[, 1]
# Frequency Percent
#Group1 12 30
#Group2 28 70
#Total 40 100出力例
・CrossTableコマンド
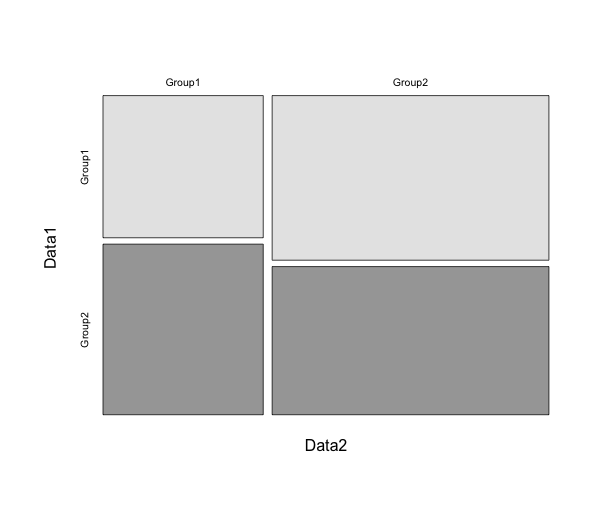
・freqコマンド
少しでも、あなたの解析が楽になりますように!!