Rでウェブ解析:データの抽出について
もはや、ウェブ解析にはなくてはならないソフトになりつつあるRですが、ネット上の情報は応用が多くなかなか基本的な情報を見つけるのは困難です。今回は解析の際には、絶対必要なデータフレームから必要なデータを抽出する例を紹介します。

解析の前準備
・ライブラリ XLConnectの導入
https://www.karada-good.net/analyticsr/r-3/
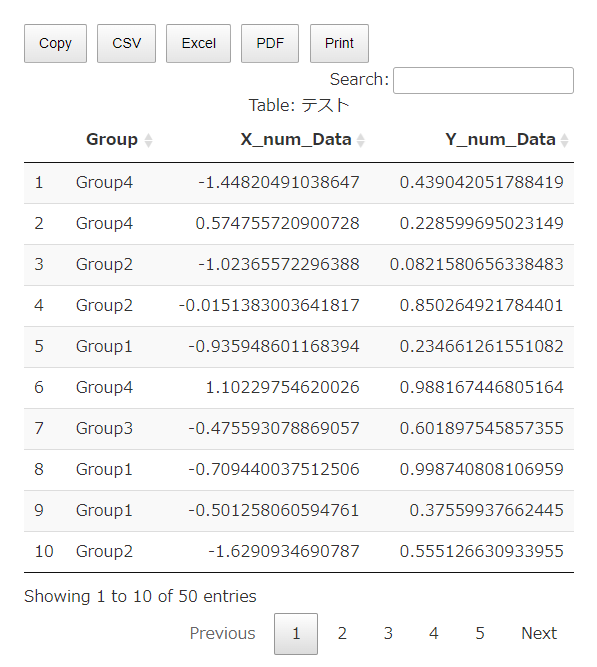
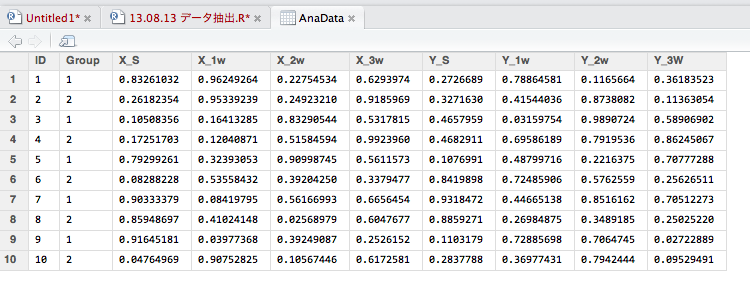
想定データは以下の画像を参照してください。
スポンサーリンク
紹介するRのコード
コードはエクセルデータを読み込み、行名に含まれる単語で必要な行を抽出し、そのデータをエクセルで出力する内容となっています。解析する際に入力する必要がある箇所は下記の通りです。*紹介するコード内で表示されている内容です。適時変更ください。
- fileName <- “テスト” #出力ファイル名
- Gtexy <- c(“2w”) #抽出する単語の設定
- ADRange_SE <- 1:2 #残したい行の設定、例えば被験者番号など
###ライブラリーの読み込み#####
library("XLConnect")
library("tcltk")
########
###データの読み込み#####
###xlxsデータ#####
###解析データ#####
sheetSelect <- 1#読み込むシート番号を入力
selectABook <- paste(as.character(tkgetOpenFile(title = "試験結果xlsxファイルを選択",filetypes = '{"xlsxファイル" {".xlsx"}}',initialfile = "*.xlsx")), sep = "", collapse =" ")
MasterAnaData <- loadWorkbook(selectABook)
AnaData <- readWorksheet(MasterAnaData, sheet = sheetSelect)
###初期Dirの設定#####
FarstDir <- as.data.frame(strsplit(selectABook, "/")) #初期dirpathの取得準備
FarstDir <- paste(FarstDir[1:(nrow(FarstDir)-1),], sep = " ", collapse = "/" ) #初期dirpathの取得
setwd(FarstDir) #初期dir設定
########
###解析する際に入力する個所#####
fileName <- "テスト" #出力ファイル名
Gtext <- c("2w") #抽出する単語の設定
ADRange_SE <- 1:2 #残したい行の設定。例えば被験者番号など
########
###解析コマンド#####
###Dataの抽出#####
for ( n in 1:length(Gtext)){
include_with_text <- grep(Gtext[n],colnames(AnaData),value = TRUE) #行抽出の準備
SelectDF <- subset(AnaData,select = include_with_text) #行の抽出
ExMaster <- cbind(AnaData[,ADRange_SE],SelectDF) #抽出データの結合
writeWorksheetToFile(paste(format(Sys.time(), "%y.%m.%d")," ", fileName, ".xlsx", sep = ""), data= ExMaster, sheet= Gtext[n])
assign(paste("AnaData_", n, sep = ""), ExMaster, envir = .GlobalEnv) #"AnaData_" + Gtextで変数を作成し情報を格納
}
########
###統合データの作成#####
if (1 < length(Gtext)){
#抽出データが2以上の場合
NewFile <- AnaData[,ADRange_SE]
for ( n in (ADRange_SE[length(Gtext)] + 1):ncol(AnaData_1)) {
for (o in 1:length(Gtext)){
NAD <- eval(parse(text = paste("AnaData_",o, sep = "")))[,n]
NAD <- as.data.frame(NAD)
colnames(NAD) <- iconv(colnames(eval(parse(text = paste("AnaData_",o, sep = "")))[n]),"cp932","UTF-8")
NewFile <- cbind(NewFile,NAD)
}
}
colnames(NewFile) <- iconv(colnames(NewFile),"cp932","UTF-8")
writeWorksheetToFile(paste(format(Sys.time(), "%y.%m.%d")," ", fileName, ".xlsx", sep = ""),data=NewFile,sheet = "統合データ" ) #新データフレームの書き出し
}else{
#抽出データが1の場合何もしない
}
########出力例
・抽出する単語をGtexy <- c(“X”)に設定した出力
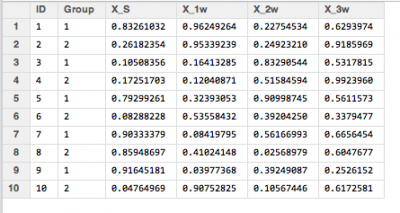
抽出の基本コマンドさえ押さえておけば、発展的に利用できると思います。
・抽出する単語をGtexy <- c(“2w”)に設定した出力
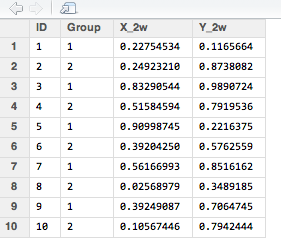
皆様のウェブ解析にお役に立ちますように。
もし、不明点がありましたらこちらからお問い合わせください。

スポンサーリンク