データ内の欠損値を含むデータの削除、データ名の整形、指定値を欠損値に変換するコマンドが収録されているパッケージの紹介です。
「dplyr」パッケージと組み合わせると、とても便利だと思います。
・Rで解析:data.frameの操作が楽々な「tidyr」パッケージ
https://www.karada-good.net/analyticsr/r-491/
パッケージバージョンは2.1.0.9000。実行コマンドはR version 4.2.2で確認しています。
パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("devtools")
devtools::install_github("sfirke/janitor")実行コマンドの紹介
詳細はコマンド、パッケージのヘルプを確認してください。
#パッケージの読み込み
library("janitor")
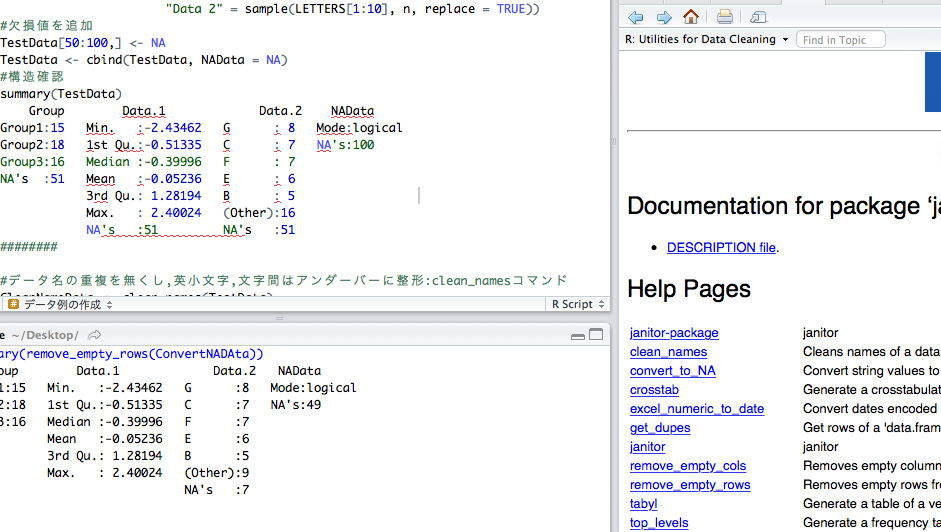
###データ例の作成#####
n <- 100
TestData <- data.frame("Group" = sample(paste0("Group", 1:3), n, replace = TRUE),
"Data 1" = sample(rnorm(10), n, replace = TRUE),
"Data 2" = sample(LETTERS[1:10], n, replace = TRUE))
#欠損値を追加
TestData[50:100,] <- NA
TestData <- cbind(TestData, NAData = NA)
#構造確認
summary(TestData)
Group Data.1 Data.2 NAData
Length:100 Min. :-1.36203 Length:100 Mode:logical
Class :character 1st Qu.:-0.72351 Class :character NA's:100
Mode :character Median : 0.03051 Mode :character
Mean :-0.01202
3rd Qu.: 0.63263
Max. : 1.21745
NA's :51
########
#データ名の重複を無くし,英小文字,文字間はアンダーバーに整形:clean_namesコマンド
CleanNameData <- clean_names(TestData)
#確認
colnames(CleanNameData)
[1] "group" "data_1" "data_2" "nadata"
#欠損値のみの行を削除:remove_emptyコマンド
#summary(remove_empty(ConvertNADAta))少しでも、あなたの解析が楽になりますように!!