データ名で数字の桁数が揃っていないために、sortコマンド等で期待した通りに並ばなかった経験はないでしょうか。意外とデータ名の修正は面倒です。そんな手間を軽減するパッケージの紹介です。
パッケージバージョンは1.4.2。実行コマンドはwindows 11のR version 4.1.2で確認しています。
パッケージのインストール
下記コマンドを実行してください。
#パッケージのインストール
install.packages("strex")コマンドの紹介
詳細はパッケージのヘルプを確認してください 。
#パッケージの読み込み
library("strex")
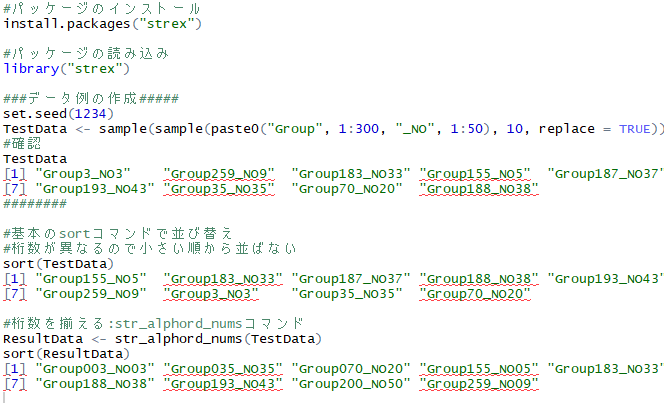
###データ例の作成#####
set.seed(1234)
TestData <- sample(sample(paste0("Group", 1:300, "_NO", 1:50), 10, replace = TRUE))
#確認
TestData
[1] "Group3_NO3" "Group259_NO9" "Group183_NO33" "Group155_NO5" "Group187_NO37" "Group200_NO50"
[7] "Group193_NO43" "Group35_NO35" "Group70_NO20" "Group188_NO38"
########
#基本のsortコマンドで並び替え
#桁数が異なるので小さい順から並ばない
sort(TestData)
[1] "Group155_NO5" "Group183_NO33" "Group187_NO37" "Group188_NO38" "Group193_NO43" "Group200_NO50"
[7] "Group259_NO9" "Group3_NO3" "Group35_NO35" "Group70_NO20"
#桁数を揃える:str_alphord_numsコマンド
ResultData <- str_alphord_nums(TestData)
sort(ResultData)
[1] "Group003_NO03" "Group035_NO35" "Group070_NO20" "Group155_NO05" "Group183_NO33" "Group187_NO37"
[7] "Group188_NO38" "Group193_NO43" "Group200_NO50" "Group259_NO09"
#文字列に含まれる数字を取得:str_extract_numbersコマンド
str_extract_numbers(TestData)
[[1]]
[1] 3 3
[[2]]
[1] 259 9
#以下省略
#指定文字が初出現より前方文字列を取得:str_before_firstコマンド
#後方はstr_after_firstコマンド
str_before_first(TestData, pattern = "3")
[1] "Group" NA "Group18" NA "Group187_NO" NA "Group19"
[8] "Group" NA "Group188_NO"
#指定文字の最後尾より前方文字列を取得:str_before_lastコマンド
#後方はstr_after_lastコマンド
str_before_last(TestData, pattern = "3")
[1] "Group3_NO" NA "Group183_NO3" NA "Group187_NO" NA "Group193_NO4"
[8] "Group35_NO" NA "Group188_NO"
#指定出現数より前方文字列を取得:str_before_nthコマンド
#後方はstr_after_nthコマンド
str_before_nth(TestData, pattern = "5", n = 2)
[1] NA NA NA "Group15" NA NA NA
[8] "Group35_NO3" NA NA 少しでも、あなたの解析が楽になりますように!!